

When I was first starting out with SQL Server, I had a hard time understanding the difference between COUNT(*) and COUNT(column), and how they are used with the GROUP BY clause.
Many times, the COUNT(*) function would return the same results as the COUNT(<column>) function, so I just told myself “Who cares what the difference is, they’re returning the same results anyway“.
Here is “who cares”: Your boss, and your clients if your queries end up returning inaccurate information.
It is definitely important to understand the difference between COUNT(*) and COUNT(<column>) in the real world.
In this tutorial, we’ll talk about the difference between the two aggregates and when one should be used over the other. We’ll cover these topics:
- What’s the difference between COUNT(*) and COUNT(<column>)?
- Examples of COUNT(*) vs COUNT(<column>)
- Tips, tricks, and links
So, let’s do it.
(By the way, not sure why there is a lady vampire as the featured image? According to ancient folklore, vampires suffer from an obsessive compulsive condition known as Arithmomania, which is an obsession with counting. Link)
1. What’s the difference between COUNT(*) and COUNT(<column>)
COUNT(*) is used when you simply want to count the number of rows per group, no matter what values exist in the columns. COUNT(<column>) will count the number of rows per group that have a non-NULL value in the specified column.
Most books on the topic of querying databases using T-SQL will say the difference is simply this: COUNT(<column>) excludes NULL while COUNT(*) does not.
When I was first learning T-SQL, this wasn’t thorough enough for me. Now that I do understand the difference, I see what they mean.
We’re going to give you some examples next, which is honestly the best way to understand the difference.
2. Examples of COUNT(*) vs COUNT(<column>)
Let’s look at an example of each
The COUNT(*) aggregate function
As I said in the last point, the COUNT(*) aggregate function will simply count the number of rows per group.
It really doesn’t care what values are in your other columns.
(When I say “other” columns, I mean columns you are NOT grouping by)
Say we have a table called EmployeeDetails with the following data:
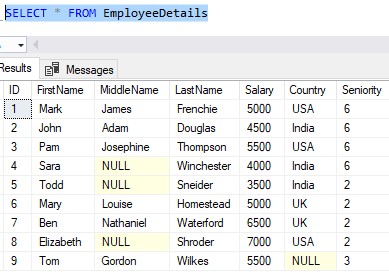
Let’s say you want to write a simple query to see the number of Employees you have in each Country.
Pop Quiz: What would we be “grouping by” in a query like that?
Answer: The different Country values.
Need a rundown on the GROUP BY clause? Click the link!
When thinking about the COUNT(*) function, you really have to put blinders on to ignore the other column values.
What if we look at the same result set from the query above, but we hide the other column values besides the Country column:
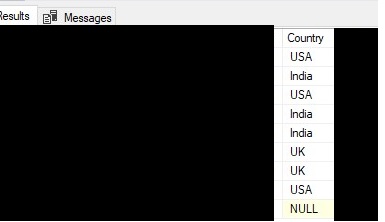
This is how the COUNT(*) function, grouping by the Country column, would see the data.
It just counts the number of rows per group.
We already established the “groups” are the different Country values. So it looks like we have the following breakdown:
USA – 3 rows
UK – 2 rows
India – 3 rows
NULL – 1 row
So if we run our query with the GROUP BY clause, grouping by Country and with the COUNT(*) function, we should see the same breakdown:
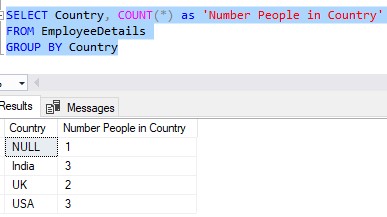
Nice.
The COUNT(<column>) aggregate function
When you use the COUNT(<column>) aggregate function, you are basically saying: For each group, count the number of rows that don’t have NULL in the specified column.
Let’s think about a good example.
What if you want to count the number of people in each Country that have a middle name?
Since we’re still counting something, we still need to use one of our COUNT functions and a GROUP BY clause, but now we are, in fact, concerned with what values are in another column (the MiddleName column).
The query looks like this:

Going back to our blinders, SQL Server will look at the data in the EmployeeDetails table like this now:
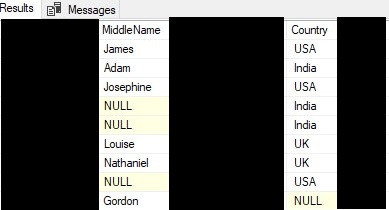
We’re still going to group the results by Country. But now, for each country, we’re going to count the number of rows that have a NON-NULL value in the MiddleName column.
So, for the group USA, how many rows have a MiddleName that is not NULL?
Answer: 2
For group India, how many rows have a MiddleName that is not NULL?
Answer: 1
You get the idea.
Here is the output of our new query:
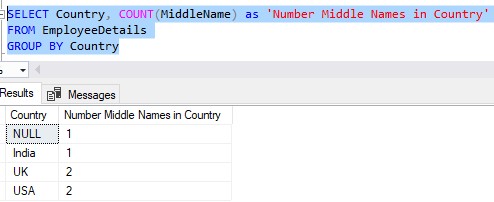
I hope you’re not thrown off by the Country ‘NULL‘.
In the EmployeeDetails table, we saw there is an employee with a Country of NULL. We still include that as one of our groups. And for that employee, there is a MiddleName value, so we count it.
AKA: The NULL group has 1 person with a middle name.
As you can see, it’s important to know the difference between the two COUNT functions. They can definitely give you different results if you don’t know how they work!
3. Tips, Tricks and Links
Here is a list of a few tricks and tricks you should know when working with COUNT(*) and COUNT(<column>)
Tip # 1: When using either COUNT aggregate function, you actually don’t need to use it with the GROUP BY clause
If the only expression in your SELECT list is the aggregate function (and no other table columns), you don’t need a GROUP BY clause. The “group” in that case would be the one entire result set.
For example, what if you simply want to know the number of people with Middle Names in your EmployeeDetails table? You could definitely run a query like this:
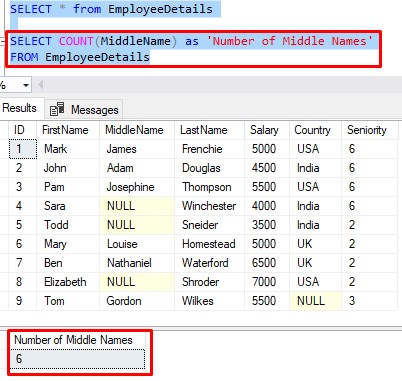
This factoid is true for other aggregate functions, too, and not just the COUNT aggregates.
Tip # 2: When using COUNT(<column>), you can include the words ALL or DISTINCT next to the column name.
The syntax would be either COUNT(ALL <column>)or COUNT(DISTINCT <column>)
COUNT(ALL <column>) is actually the default behavior. When you use COUNT(<column>), it is actually doing a COUNT(ALL <column>)behind the scenes. It will count the number of non-NULL rows for each group, even if there are multiple rows with the same column value.
But what if you wanted to not count duplicate values? In that case, you should choose to use COUNT(DISTINCT <column>)
Let’s look at an example. What if you want to know how many different countries your Employees are in? You start with this:
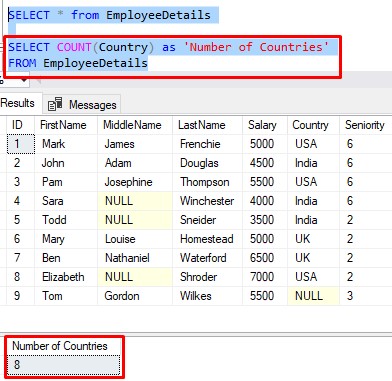
Remember, COUNT(<column>) is actually doing a COUNT(ALL <column>) behind the scenes. So this query is just counting the number of rows in our table with a non-NULL value in the Country column.
Period.
But the number 8 isn’t really the answer to our question, is it?
Sure, there are 8 non-NULL Country values, but many of them are repeated. We’re really looking for the number of distinctly different Countries in our EmployeeDetails table.
This is where you would use the keyword DISTINCT:
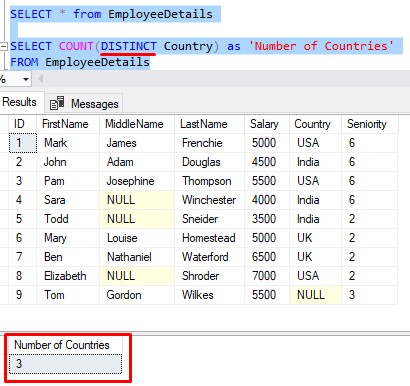
That’s better.
Links
There is a great book called T-SQL Fundamentals written by Itzik Ben-Gan that goes over several core concepts you should know about SQL Server, including a discussion about aggregate functions. You won’t regret owning this book, trust me. Definitely get it today!

Next Steps:
Leave a comment if you found this tutorial helpful!
Are you making these 7 mistakes with NULL? Click the link to find out?
If you’re not already familiar with the HAVING clause, you should read up on that, too. We basically use it to filter the results of an aggregation. Click the link below to learn more:
The HAVING Clause: How it works
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, please leave a comment. Or better yet, send me an email!


