

A proper understanding of First Normal Form (and normalization in general) is very important if you are looking to enter the field of database development and design.
I have combed the internet and referenced several books I own on the topic of database development and design, and they all have a slightly different set of rules you should follow to make sure a table is in First Normal Form. This tutorial provides a summary of everything people are saying! If you follow all these rules, your tables will definitely be off to a great start.
In this tutorial, we’re going to break down the concept of table normalization and discuss the first set of rules you should follow when designing tables in your database.
There are 3 “normal forms” you should know when designing tables in your database. This tutorial discusses the first normal form, but make sure you read up on the Second Normal Form, and also Third Normal Form.
After reading these tutorials, you will have a very solid understanding of normalization and you will be able to create tables that are very efficient and will stand the test of time.
In this first tutorial, we will discuss the following topics about First Normal Form:
- What is normalization anyway?
- Tables should contain unique rows
- Columns should be “atomic”
- Tables should not have repeating groups
- Values in each column should all be the same data type
Everything discussed in this tutorial can also be found in the following FREE Ebook:
FREE Ebook on SQL Server Table Normalization!

This FREE Ebook provides an excellent summary of all the rules you need to know when normalizing your tables to First, Second, and Third Normal Form. It will definitely be a great resource to keep and reference throughout your career as a data professional. Make sure you download the guide today!
Let’s jump right in.
1. What is normalization anyway?
You should know a simple definition for what “Normalization” is:
Normalization is the process of applying a set of rules to tables in our database to maintain data integrity and reduce data redundancy.
That last part is key: Reduce data redundancy.
One of the main goals you should always think about when designing your tables is to eliminate the need to update/delete data in more than one place. If you need to update a value, you want to make sure you need to update it in only one place, and not several.
To show you what I mean, let’s see a very bad example of a table. Here is an Orders table that keeps track of products ordered for our business:
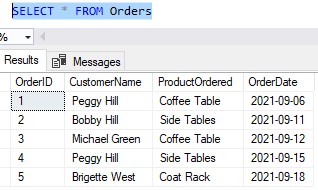
This table shows us:
- The Order ID of the order
- Who made the order
- What product they bought
- The date they made the purchase
One might think this table is pretty solid, but let’s think about a problem that might occur. What if Peggy Hill’s name changes? Maybe she get’s married ( or divorced 🙁 ) and her last name changes. Since she is referenced twice in this table, it means we’ll need to change her name in both places.
Sure, that’s easy enough to do with only two rows, but what if our table contained ten’s of thousands of rows, and Peggy Hill were referenced hundreds of times? We would need to find each and every row and make the change. Does that sound like a lot of work? (say yes)
We encounter the same problem for our Products, too. What if we want to change the product “Side Tables” to “End Tables“? We need to change it in multiple places!
This is why we need normalization. We want to do our best to eliminate update anomalies like in our example.
(An update anomaly is when you basically need to update data in more than one location. Not good!)
Now that you know why we need normalization, let’s talk about the rules you should follow to make sure your tables meet First Normal Form.
2. Tables should contain unique rows
This first one is easy. No two rows in a table should contain the exact same information.
This rule is satisfied with the introduction of a Primary Key constraint to your table. A primary key constraint basically forces values in a column (or set of columns) to contain unique values. If a column value is truly unique, it can be said the whole row is unique.
So all you need to do to satisfy this portion of First Normal Form is introduce a primary key constraint to your table, which you should be doing anyway.
Take a look at the full tutorial on the primary key constraint to learn more:
SQL Server Primary Key Constraint: How it works and 6 rules you need to know
3. Columns should be “atomic”
When most people discuss First Normal Form, this is the rule they are mainly talking about.
All columns in your table need to be atomic.
Which begs the question: What the f*ck does “atomic” mean?
In the context of SQL, atomic means each column can contain only one value per row. You shouldn’t try to squeeze in multiple values into a single column.
Let’s think about an example. Take a look at the following Employees table:
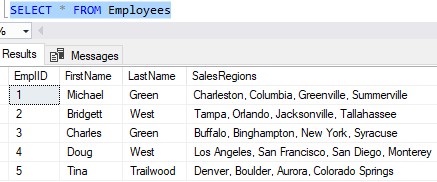
This table keeps track of some basic Employee information, including their unique EmplID, First and Last name, and the cities they are responsible for selling our products in.
Does the last column, SalesRegions, seem a bit odd to you?
This column is considered a violation of First Normal Form. The column does not contain a single value for each row.
(The column is not atomic).
In this case, we need to think about how we could split this up to satisfy First Normal Form.
Splitting up tables
To make this table atomic, what should we do? We cannot assign only one city to each Employee because that would simply be inaccurate. For example, we can’t just change Michael Green to be assigned to only Charleston when, in real life, he is assigned to more than just that city.
Also, we shouldn’t create more than one row for Michael Green, where each row has a different city. Remember what I said about update anomalies. If Michael Green’s name needs to change, we would need to update it in multiple rows!
In this case, the best thing we should do is create another table to track each sales region and the employee responsible for it. A table like this:
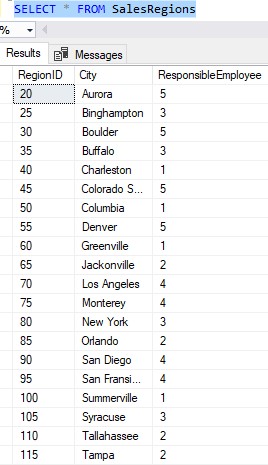
See how each city has the ID of the Employee who’s responsible for it? If we want to see more details for the Employee (like their First and Last names), we just need to do a simple INNER JOIN between the Employees table and the SalesRegions table:
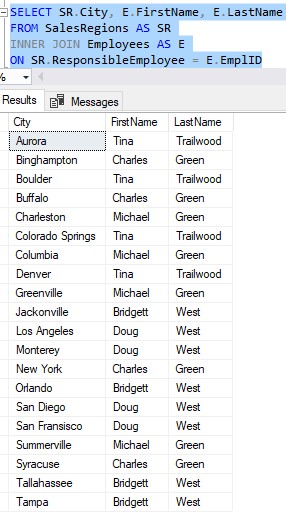
Then, back in the Employees table, we don’t need the SalesRegion column anymore. We can just drop it:
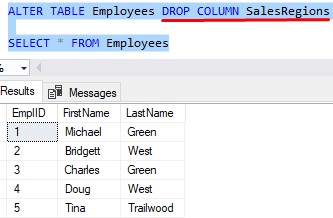
Again folks, when most people talk about putting a table in First Normal Form, this is what they’re talking about. We want all our columns to be atomic, a.k.a. only one value per column. This usually means we’ll need to split data into multiple tables like we have done, and that’s ok! You’ll find that much of normalization involves splitting up data across multiple tables.
Let’s move on to the next rule about First Normal Form.
4. Tables should not have repeating groups
Let’s revisit our first, incorrect version of the Employees table where we had multiple cities in the SalesRegions column.
What if instead of having multiple cities in one column, we did something like this:
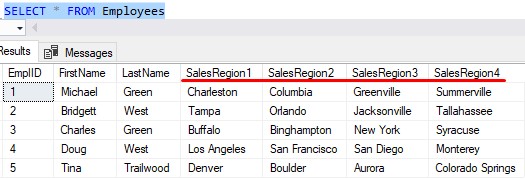
Instead of having four values in one column, we made four columns that each have one value.
Maybe we think we hacked the atomic rule of First Normal Form. Sure, technically each column is atomic now.
But again folks, this is considered bad design. The new SalesRegion columns are basically repeating, and another rule about First Normal Form is that you eliminate repeating groups.
As the table is now, think about if we wanted to add a fifth city for any of our Employees. We would need to add a new column, right? That would kinda suck.
Also, think about a query where we simply want to know who is responsible for a specific city. For example, what if we want to know who is responsible for the city of Tallahassee? Since we need to look in 4 different columns, the query would look like this:
SELECT * FROM Employees WHERE SalesRegion1 = 'Tallahassee' or SalesRegion2 = 'Tallahassee' or SalesRegion3 = 'Tallahassee' or SalesRegion4 = 'Tallahassee'
Does that seem a bit repetitive? (say yes)
Any time you see Column1, Column2, Column3, etc. in a table, it’s a red flag that it’s violating First Normal Form.
The solution is just like we saw before, where we create a separate SalesRegions table that references the Employee ID of the employee responsible for the city, and then dropping the 4 SalesRegion columns in our Employee table.
Again folks, I’ll say it again. Much of normalization comes down to splitting data up across multiple tables and creating links between them. Get comfortable with it!
5. Values in each column should all be the same data type
This rule is a bit trivial, but it’s something I’ve read about and think it’s worth discussing.
Every value in a column needs to be the same data type.
Let’s revisit our SalesRegions table:
The ResponsibleEmployees column is an INT data type. This means we can’t put anything but an integer value into this column.
I say this rule is a bit trivial because SQL Server won’t let us put anything but an integer value into this column. For example, this INSERT statement doesn’t work:
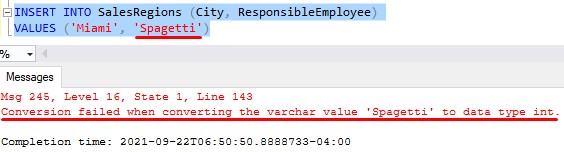
We can’t put the word ‘Spagetti’ in an integer column. Duh!
And don’t be fooled by implicit conversions either. Let’s insert the number 951 as the name a new City:
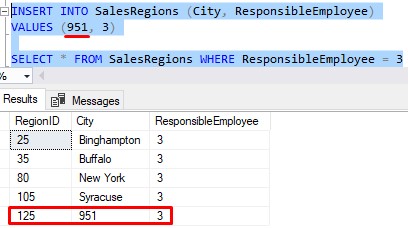
This appears to have put an integer value in a VARCHAR column, right?
Not exactly. When SQL Server inserted the value 951, it actually implicitly converted it to the character string ‘951’.
We can use the handy SQL_VARIANT_PROPERTY system function to see the data types of our values:
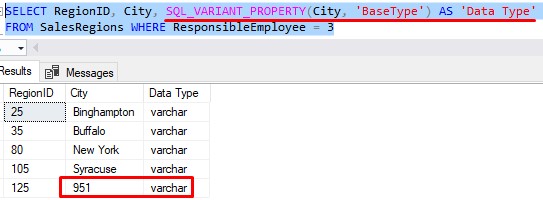
So again, SQL Server is either going to implicitly convert values to the correct data type, or it simply won’t let you enter a value with an improper data type.
That’s why I say it’s trivial, but it’s worth knowing!
Next Steps:
Leave a comment if you found this tutorial helpful!
If you found this tutorial helpful, make sure you download your FREE Ebook:
FREE Ebook on SQL Server Table Normalization!
This FREE Ebook provides an excellent summary of all the rules you need to know when normalizing your tables to First, Second, and Third Normal Form. It will definitely be a great resource to keep and reference throughout your career as a data professional. Make sure you download the guide today!
Now that you’ve mastered First Normal Form, you should definitely check out the rules for Second Normal Form and Third Normal Form. They introduce more rules you should follow to make sure your tables preserve data integrity and reduce data redundancy. Check them out!
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, or if you are struggling with a different topic related to SQL Server, I’d be happy to discuss it. Leave a comment or visit my contact page and send me an email!


