

When querying data in a SQL Server database, there may be times when you want to rank rows in your dataset. Maybe you want to rank Customers by how much they have spent in your store, or maybe you want to rank Products from most expensive to least expensive. SQL Server offers a few different ranking window functions you can use to achieve that goal.
This tutorial assumes you know what a window function is to begin with. For example, we’ll be using terms like “window partition” and “window frame”. If you don’t know what those mean, you should definitely check out my beginner-friendly introduction to window functions, found here:
SQL Server Window Functions: An introduction for beginners
There are several different window functions in SQL Server, but in this tutorial we’re going to focus on the different ranking window functions. They are: ROW_NUMBER, RANK, DENSE_RANK, and NTILE.
Also, make sure you download your FREE Ebook:
FREE Ebook on SQL Server Window Functions!

This FREE Ebook discusses absolutely everything you need to know about window functions in SQL Server, including everything discussed in this tutorial. This eBook will definitely be a great resource for you to reference throughout your career as a data professional. Get it today!
We’ll discuss these topics:
- Rules for ranking window functions
- Setting up some data
- The ROW_NUMBER window function
- The RANK window function
- The DENSE_RANK window function
- The NTILE window function
- Links
Let’s get into it:
1. Rules for ranking window functions
There are only a few rules you need to remember when working with ranking window functions:
- We use the OVER clause in all ranking window functions. This is actually true for all window functions. One could say the OVER clause is the heart of a window function.
- You can only specify a ranking window function in the SELECT list or an ORDER BY clause. This is also true for all window functions.
- They don’t take any arguments (except for NTILE which takes an integer as an argument)
- You don’t specify a window frame
- They do require the use of a window order clause
The use of a window order clause makes perfect sense, because how are you supposed to rank things if they aren’t in some kind of order?
2. Setting up some data
To understand how the ROW_NUMBER function works, we need to set up some data. If you have been following along with any of the other window function tutorials, you will already have this data set up in your environment.
Run these SELECT statements to see if you already have the data:
SELECT * FROM Customers SELECT * FROM Products SELECT * FROM Orders
The data should look like this:
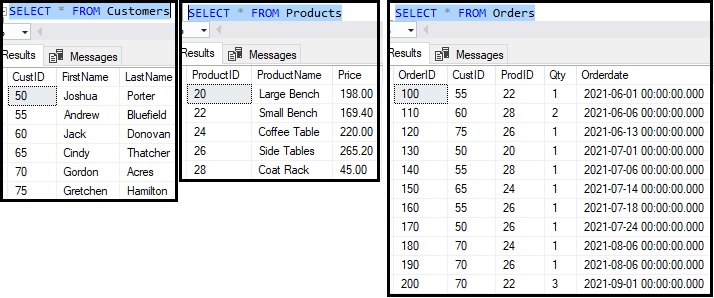
If you don’t have the data, let’s go ahead and add it. Here’s the Customers table:
--Create Customers table
CREATE TABLE Customers
(
CustID INT PRIMARY KEY IDENTITY(50,5),
FirstName VARCHAR(20),
LastName VARCHAR(20)
)
--Populate Customers it with data
INSERT INTO Customers(FirstName, LastName)
VALUES
('Joshua','Porter'),
('Andrew','Bluefield'),
('Jack','Donovan'),
('Cindy','Thatcher'),
('Gordon','Acres'),
('Gretchen','Hamilton')
The Products table:
--Create Products table
CREATE TABLE Products
(
ProductID INT PRIMARY KEY IDENTITY(20,2),
ProductName VARCHAR(20),
Price DECIMAL(5,2)
)
--Populate Products table with data
INSERT INTO Products (ProductName, Price)
VALUES
('Large Bench',198.00),
('Small Bench',169.40),
('Coffee Table',220.00),
('Side Tables',265.20),
('Coat Rack',45.00)
Finally, the Orders table:
--Create Orders table CREATE TABLE Orders ( OrderID INT PRIMARY KEY IDENTITY(100,10), CustID INT, ProdID INT, Qty TINYINT, Orderdate DATETIME ) --Populate Orders table with data INSERT INTO Orders(CustID, ProdID, Qty, Orderdate) VALUES (55, 22, 1, '6/1/2021'), (60, 28, 2, '6/6/2021'), (75, 26, 1, '6/13/2021'), (50, 20, 1, '7/1/2021'), (55, 28, 1, '7/6/2021'), (65, 24, 1, '7/14/2021'), (55, 26, 1, '7/18/2021'), (50, 26, 1, '7/24/2021'), (70, 24, 1, '8/6/2021'), (70, 26, 1, '8/6/2021'), (70, 22, 3, '9/1/2021')
Notice the Orders table contains unofficial foreign key links to both the Customers and Products tables. I say they are “unofficial” because I didn’t actually create a foreign key constraint between the tables. It’s not necessary for this tutorial.
Ok, now that we have some data set up, we can show you some examples of ranking window functions.
3. The ROW_NUMBER window function
The ROW_NUMBER function simply gives you a unique incrementing integer for every row in a window partition.
Let’s look at an example. We’ll run a quick SELECT statement with two JOINS to see some very useful information about each of our orders:
Here’s the query:
SELECT C.CustID, C.FirstName, C.LastName, P.ProductName, P.Price as 'Product Price', O.Qty, O.OrderDate FROM Orders as O INNER JOIN Customers AS C ON O.CustID = C.CustID INNER JOIN Products as P ON O.ProdID = P.ProductID
And the result set:
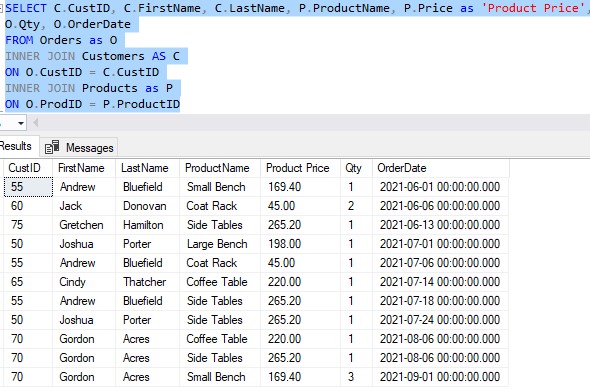
In this result set, we can see some really great details about each order. We can see the following details:
- Who made the order
- What they bought
- How much that product costs
- How many of that product they bought
- The date they made the order
So maybe we would like to see a row number assigned to each Order according to the date it was placed (in order by OrderDate).
We can use the ROW_NUMBER function to give us that information:
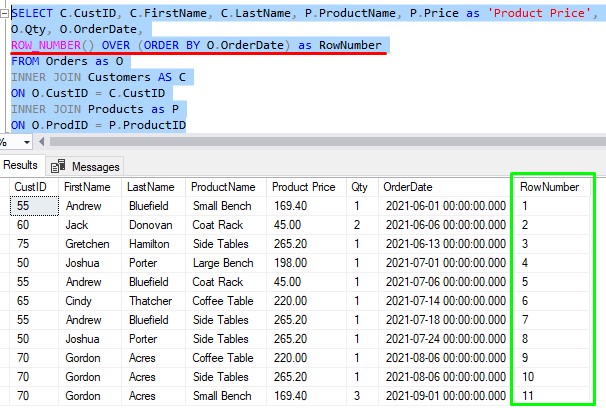
So now, each row has a unique row number in line with the OrderDate value.
Remember the rules:
- We don’t pass any arguments to the ROW_NUMBER() function
- We specify an OVER clause, and that OVER clause has a window order clause.
- You don’t specify a window frame.
I’ll also point out that since we don’t have a window partition clause within our OVER clause, the entire result set is one large partition.
The great thing about window functions is that we can introduce a window partition clause if we want to. What if we wanted to see row numbers for each customer? In other words, for each customer, we want to see row numbers that align with when they placed each order.
If we put a partition clause by CustID, we’ll see a breakdown for each customer:
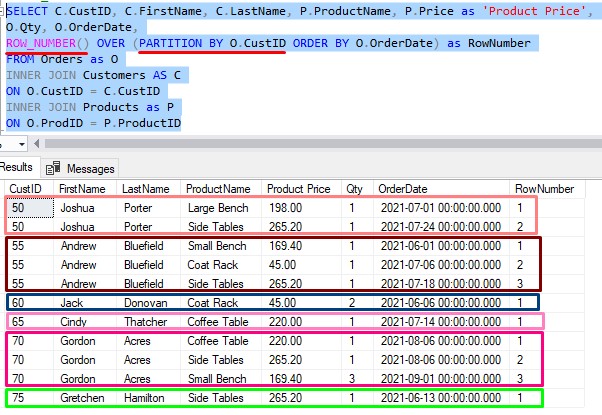
Now, we see a breakdown for each individual customer. We assign a unique row number to each row for each customer, which might be useful to see.
4. The RANK window function
RANK will return an incrementing integer for every row in a window partition, starting with 1, according to an ordering you specify. It will produce the same rank value for rows with the same ordering value.
The RANK function is actually very similar to ROW_NUMBER, if you think about it. The only difference is that RANK will produce the same rank value for rows with the same ordering value.
Going back to our first screenshot for ROW_NUMBER where we leave out the partition clause, notice the rows for our customer Gordon Acres:
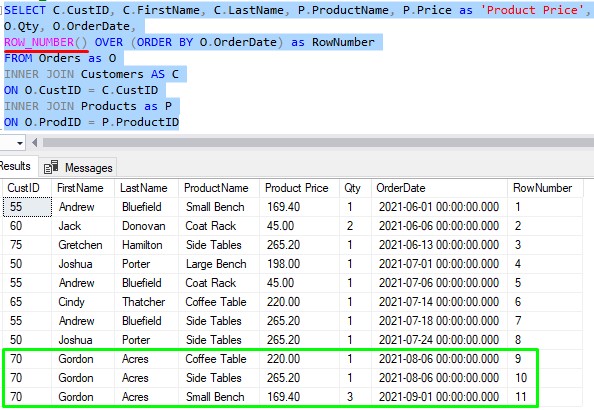
The first two rows have the same ordering value. A.K.A the same OrderDate value of 8/6/2021.
If we change the query from using ROW_NUMBER to using RANK, we see that RANK will give those two rows the same ranking value:
![]()
Those two rows are essentially tied in rank. It would not be appropriate to arbitrarily assign one of them a higher rank than the other, so SQL Server gives them the same rank.
Curiously, look at the third row for Gordon Acres. It has a rank of 11. When determining the rank to assign a row, SQL Server will look at the number of rows with a lower ordering value than the current row, then add 1 to it.
That last row for Gordon Acres has an OrderDate value of 9/1/2021. So, in this partition, how many rows have an OrderDate value that is less than 9/1/2021? Remember, since we don’t have a window partition clause, the entire result set is in one large partition:
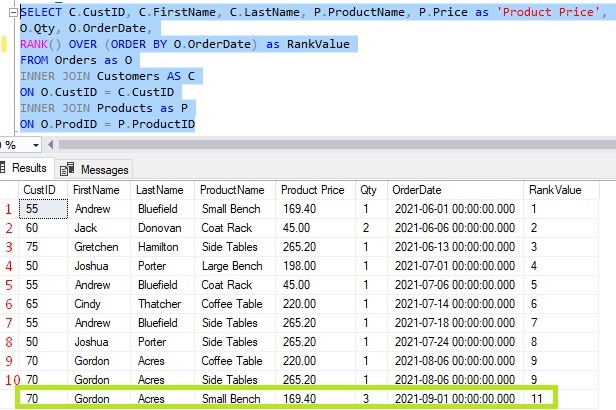
Looks like there are 10 rows with an OrderDate value that is less than 9/1/2021.
So for that last row, the RANK will be 10 + 1, which last time I checked, is 11.
The same rules apply if we specify a window partition clause.
Let’s put back the window partition clause that partitions our rows by CustID:
![]()
In the partition for Gordon Acres, the first two rows have the same ordering value since they have the same OrderDate value, so they each get a rank of 1. For the last row in that same partition for Gordon Acres, the rank will be the number of rows with a less ordering value in that partition, plus 1. Last time I checked, 2 + 1 is 3!
Which leads us to our next ranking window function…
5. The DENSE_RANK window function
DENSE_RANK will rank rows in a partition, starting with 1, according to an ordering value you specify. DENSE_RANK considers distinctness when determining the rank to assign a row.
As mentioned earlier, RANK will look at the number of rows with a lower ordering value than the current row, then add 1 to it.
DENSE_RANK will look at the number of rows with a lower distinct ordering value than the current row, then add 1 to it.
Let’s look at our window partition clause-less query and change it to use DENSE_RANK:
![]()
When looking at the third row for Gordon Acres (which has an OrderDate of 9/1/2021), how many distinct OrderDate values are less than 9/1/2021? Let’s count:
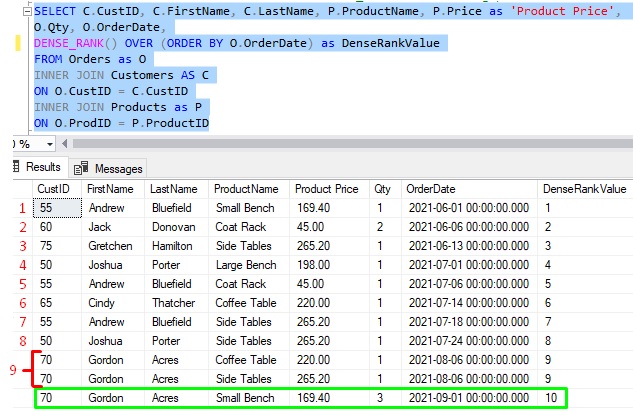
So the math is 9 + 1, which last time I checked, is 10.
Get it? This is why you might see gaps when using the RANK function, and why you won’t see gaps when using DENSE_RANK. Use the appropriate function depending on your needs!
6. The NTILE window function
NTILE allows us to collect rows in a result set into a specified number of tiles. A tile is just a group of X number of rows. Each tile is given a number, starting with 1 and ending with N.
This is a weird window function.
Let’s look at our result set without any window functions. I’ll go ahead and order the results by OrderDate:
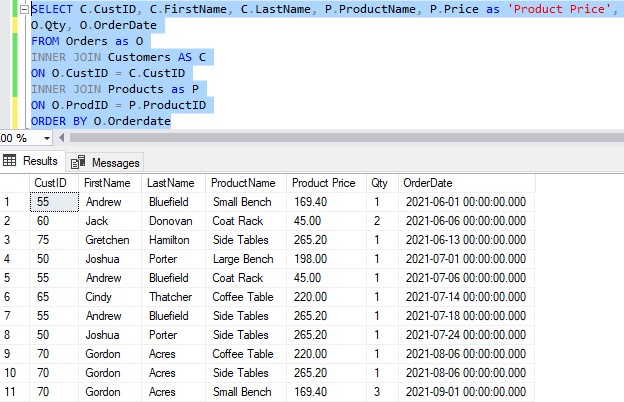
Using the NTILE function, we can collect rows into a specified number of tiles.
A tile is just a group of X number of rows. Each tile is given a number, starting with 1 and ending with N.
Let’s talk about ‘N‘ first. When you call the NTILE function, you pass as an argument the number of tiles you want to see. This “number of tiles you want to see” is going to be your ‘N‘ value.
The number of rows in each tile will be X. We determine X using a simple math formula:
X = (number of rows in partition) / (N)
An example of NTILE
We need to look at an example. Let’s say I write the following query that uses NTILE, where I specify that the number of tiles I want to see (a.k.a ‘N‘) is 5:
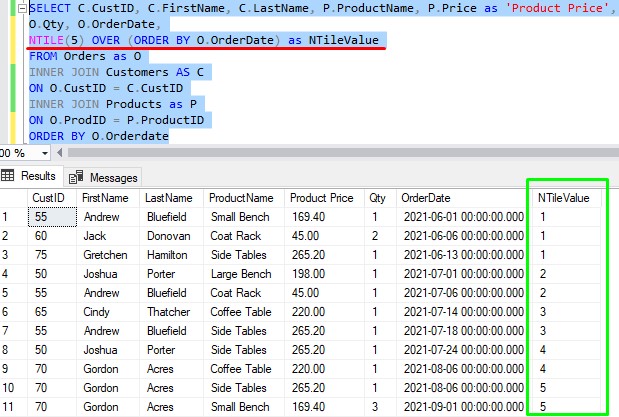
Since we didn’t specify a partition clause in our window function, the entire result set is in one large partition.
So again, the number I passed to NTILE was 5, so we see 5 tiles in our result set.
If we remember the formula, the number of rows in each tile is: (number of rows in partition) / (N)
In our case, that’s: (11) / (5), which gives us a result of 2 with a remainder of Y.
Of course, ‘Y ‘ in our case is 1.
I needed to throw in one more variable to point out something else: The first Y tiles will have an extra row in each.
If we look at the result set, we see that since we wanted to see 5 tiles, that means each tile will have a total of 2 rows in it, except for tile # 1 which will have an extra row.
Another example of NTILE
Let’s test to see if you understand. What would the result set look like if we passed an NTILE value of 4?
So that means we want to see 4 tiles. Each tile will have 2 rows in it, except the first 3 tiles which will each have an extra row:
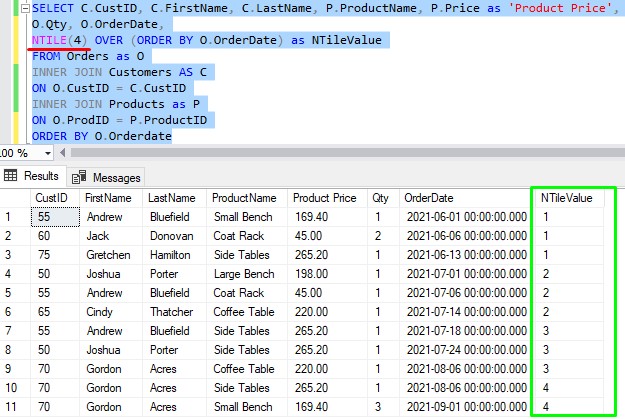
Or what about an ‘N‘ value of 6?:
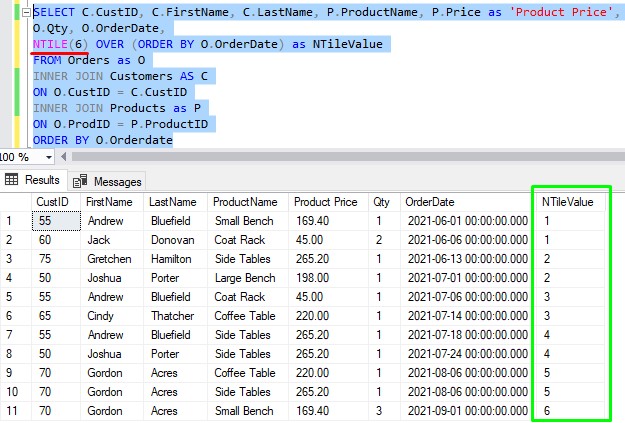
Each tile will have 1 row in it, except for the first 5 tiles which will each have an extra row.
Get it? I strongly encourage you to try this for yourself. Play around with different ‘N‘ values and see if the result is what you expect it to be.
When might you use this in the real world?
I’ve been thinking about why someone would want to see data presented in this way. What comes to mind is maybe a company wants to see data presented in groups of a percentage.
For example, if I wanted to examine the data in my Orders table, and I want to see data in 20% groups, I could write the NTILE function using an ‘N‘ value of 5.
I can be assured that all rows in the 1st tile will be the first ~20% of my orders. Rows in the 2nd tile will be next ~20% of my orders. So on and so forth. My 5th tile will be the most recent 20% of my orders.
Maybe I want to extend a special offer to those customers in the first 20%. They helped get my business off the ground, so I want to extend them a special offer of maybe “Half off their next order!“.
But for the next 20% (those people in tile # 2), maybe I still want to show them some love, but not that much love. Maybe for them, they get a coupon for “25% off their next order!“.
If someone has another example for when NTILE would be very useful, I’d love to hear it in the comments!
7. Links
Everything discussed in this tutorial can be found in the following FREE Ebook:
Download your FREE SQL Server Window Functions EBook!
This EBook discusses absolutely everything you need to know about window functions in SQL Server, including everything discussed in this tutorial. A proper understanding of window functions is essential for anyone looking to enter the field of data science. This eBook will definitely be a great resource for you to reference throughout your career. Get it today!
Next Steps:
Leave a comment if you found this tutorial helpful!
SQL Server ranking window functions are only some of the window functions we have available to us in SQL Server. If you missed the introduction to window functions, it discusses the different aggregate window functions you can use in SQL Server. That tutorial is a MUST-READ, because it discusses all the parts involved in a window function that you need to know in order to write a window function query correctly. Don’t skip that tutorial, you can find it here:
SQL Server Window Functions: An introduction for beginners
Thank you for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, or if you are struggling with a different topic related to SQL Server, I’d be happy to discuss it. Leave a comment or visit my contact page and send me an email!


