

If you are new to SQL Server and the process of database design, you’ve probably heard of the need to create a primary key column in your tables. You’ve likely been told that “every table needs a primary key“.
But do you understand why we need a primary key constraint in our tables? Do you really understand what a primary key constraint does?
A proper understanding of primary key constraints is the first step towards understanding database normalization and design. It’s very important that you know why we need a primary key constraint on our tables and that you understand the limitations put in place on a column with a primary key constraint.
In this tutorial, we’ll discuss everything you need to know about the primary key constraint and give you several important rules you need to know when designing your tables in your database.
We’ll discuss these topics:
- What is a primary key?
- A discussion about database normalization
- Syntax for creating a primary key constraint
- The best primary key column is an automatic, ever-increasing integer
- The 6 rules you should remember about SQL Server primary keys
Also, don’t forget to download your FREE Ebook:
FREE Ebook on SQL Server Constraints!

This FREE Ebook contains absolutely everything you need to know about all the different constraints available to us in Microsoft SQL Server, including:
- Primary Key constraints
- Foreign Key constraints
- Default constraints
- Check constraints
- Unique constraints
Everything found in this tutorial is thoroughly discussed in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Let’s get into it.
1. What is a primary key?
A primary key is a constraint put on a column or columns in a table to guarantee each row in a table is unique.
One aspect that makes a table relational is that it has unique rows. If there are two rows in a table with exactly the same data, that table is not considered relational.
If we add a primary key constraint to a column in a table, it basically guarantees that each row in that table will be different from every other row in the table (even if it’s only by that one column value).
Again, in that case, the table will be considered relational, which is what we want (Microsoft SQL Server is, after all, a Relational Database Management System).
One last thing you should know is that a primary key column cannot contain any NULL values. Every row must have a non-NULL value for the primary key column.
2. A discussion about database normalization
To further understand why we need a primary key column on our tables, we need to quickly go over a few simple rules about database normalization.
Normalization is basically a set of rules we apply to tables and columns in our database to maintain data integrity and reduce data redundancy.
The steps to normalizing a database are split into 5 stages (called “normal forms“). The first normal form is where we understand why we need primary key constraints.
Part of the first normal form states: All rows in a table must be unique.
In other words, we can’t have two or more rows in a table with the exact same data. If each row in a table has a unique primary key value that no other row has, then we have satisfied that portion of the first normal form.
I have a full tutorial for beginners on the basics of table normalization and First Normal Form. Check it out here:
First Normal Form: An introduction to SQL table normalization
So again folks, if we want to set ourselves up for success, we need to make sure our tables always have a primary key constraint.
3. Syntax for creating a primary key constraint
Ok, now we have a better idea of why we need a primary key constraint. Let’s talk about how you would create one.
There are a few different ways we can create a primary key constraint when creating or modifying a table. We’ll go over each one.
1. Simply using the keywords “PRIMARY KEY” next to the column you want set to be the primary key.
This is the easiest way to set a primary key constraint on a specific column. Here’s an example of a Products table with a primary key constraint on the ProductID column:
CREATE TABLE Products ( ProductID INT PRIMARY KEY, ProductName VARCHAR(20), Price DECIMAL(5,2) )
Fairly straightforward, right?
When I run this statement, the Products table will be created and a primary key constraint will also be created. The constraint is actually named, and we can see it in the object explorer (seen in the Keys folder and not the Constraints folder):
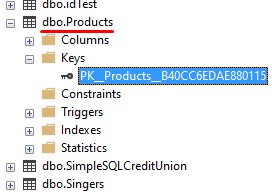
When we begin adding rows to this table, we need to make sure this ProductID column is given a unique value for every insert. If we don’t, SQL Server won’t let us add the row!
I’ll demonstrate. Let’s add a row, specifying a ProductID of 1:
-- First Insert INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Coffee Table', 198.00)
Then let’s check the data:
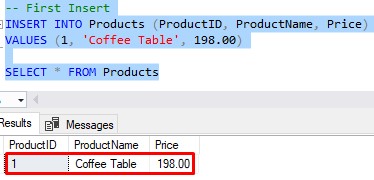
So far so good. Now let’s try to add the exact same row a second time.
-- Second Insert INSERT INTO Products (ProductID, ProductName, Price) VALUES (1, 'Coffee Table', 198.00)
We get an error message:
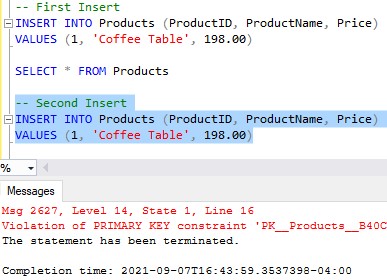
Here’s that full message:
Violation of PRIMARY KEY constraint ‘PK__Products__B40CC6EDAE880115’. Cannot insert duplicate key in object ‘dbo.Products’. The duplicate key value is (1).
Folks, this is exactly what the primary key constraint is there for. It’s there to basically force each row to be unique. I can’t enter a second row that contains exactly the same primary key value as an existing row!
But let’s try again with a different ProductID value:
-- Third Insert INSERT INTO Products (ProductID, ProductName, Price) VALUES (2, 'Coffee Table', 198.00)
Yep, that works:
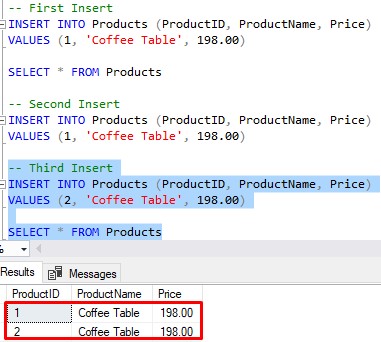
All rows in this table are now unique, aren’t they? (say yes)
2. Specifying a constraint name
In the previous example, you might have noticed how the primary key constraint was given a very long name: PK__Products__B40CC6EDAE880115
While that name is fine if you don’t really care about the name of your constraint, there is another way to create the primary key constraint if you do care about the name.
Here is an example:
--Drop the old instance of Products DROP TABLE Products --Create new instance of Products table with Constraint name specified CREATE TABLE Products ( ProductID INT CONSTRAINT pk_Products PRIMARY KEY, ProductName VARCHAR(20), Price DECIMAL(5,2) )
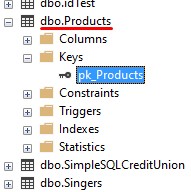
Next to the column we want to use as the primary key, we outline the CONSTRAINT keyword, followed by whatever name we want to give the constraint, followed by the kind of constraint we want (in our case, a PRIMARY KEY constraint).
If we look at the constraint in object explorer, we see it was given the name!
3. Creating the primary key constraint after the column list
The final way we can create a SQL Server primary key constraint is by outlining the constraint after the column list, instead of directly next to the column we want to use as the primary key.
Here’s what it looks like:
--Drop old instance DROP TABLE Products --New instance CREATE TABLE Products ( ProductID INT, ProductName VARCHAR(20), Price DECIMAL(5,2), CONSTRAINT pk_Products PRIMARY KEY(ProductID) )
Notice it’s very similar to the previous example. We can still specify the name we want to give the constraint, which is great. But notice we needed to specify which column we wanted to set the constraint on.
This is how you would create what’s called a composite primary key (a primary key composed of multiple columns). For example, if we wanted to say our primary key was the combination of the ProductID and the ProductName, we could do that:
CREATE TABLE Products ( ProductID INT, ProductName VARCHAR(20), Price DECIMAL(5,2), CONSTRAINT pk_Products PRIMARY KEY(ProductID, ProductName) )
Easy peasy.
4. The best primary key column is an automatic, ever-increasing integer
In the previous point, we demonstrated a problem that can happen when adding rows to a table that has a primary key constraint. Remember when we tried to add two rows with the same ProductID value?:
It was easy enough to see what we did wrong in our second insert. Of course, we were trying to specify a ProductID of 1 when there was already a ProductID of 1 in the table!
It was easy enough to see the mistake and change our second insert to use a different primary key. But what if there were tens of thousands of rows in the database? Do you think it would be difficult to tell if the number we want to use is already being used? (say yes).
The IDENTITY property
Luckily, there is an easy way to basically let SQL Server handle the creation of integer values for a column. We can add the IDENTITY property to a column that we want to set as the primary key:
CREATE TABLE Products ( ProductID INT IDENTITY CONSTRAINT pk_Products PRIMARY KEY, ProductName VARCHAR(20), Price DECIMAL(5,2) )
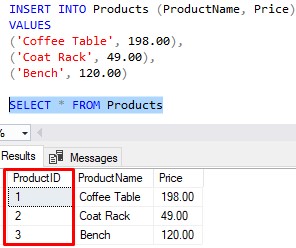
Now, SQL Server will handle the task of adding a new value to the ProductID column when we insert new rows. In the INSERT statement, we would NOT specify a value for that column:
INSERT INTO Products (ProductName, Price)
VALUES
('Coffee Table', 198.00),
('Coat Rack', 49.00),
('Bench', 120.00)
Let’s check the data:
Awesome, now that’s one less thing we need to do!
Special note: The IDENTITY property does not enforce uniqueness.
The property simply keeps track of the last integer value it generated for a table, then increments that number each time an INSERT is performed. It does not check to see if a value was generated previously. That uniqueness validation is handled by the primary key constraint, of course.
It just so happens that as long as you don’t f*ck with it, the IDENTITY values being generated ought to be unique anyway.
Check out the full tutorial on the IDENTITY property to learn more:
IDENTITY Column in SQL Server: Everything you need to know
A clustered index is created on the primary key column(s) automatically
Another reason an integer is great to have as our primary key column is because behind the scenes, SQL Server is going to automatically create a clustered index for our table, where the clustered index key is the primary key column.
Let’s think about the clustered index data structure. It orders data on disk in order by the clustered index key. So if the ProductID column becomes the clustered index key, we can say the data is physically ordered on disk in order by ProductID.
What if we add a new row to the table? Well, the new ProductID would just get tacked on to the end of the clustered index data structure, which is easy to do. If we add another row, it gets tacked on to the end again. So on and so forth. Tacking onto the end is easy.
But think about what would happen if we didn’t have a ProductID column, and decided to use the ProductName column as our primary key.
Whenever we add a new row, the ProductName might get tacked on to the end, but there’s a better chance it will need to go somewhere in the middle. That means data shifting needs to occur, which takes time.
Data shifting and foreign key references
Think about if a ProductName needs to change. Again, data shifting might need to happen. But also, if the column is referenced as a Foreign Key in some other table, any references to the ProductName will need to be updated there too 🙁
If we have a simple integer column as a primary key, maybe we don’t really care what the value is, and therefore probably won’t need to change it. No data shifting, and no foreign key reference changes.
Lastly, the INT data type is relatively small, only using 4 byte to store a value. Compare that to our ProductName column that uses 20 bytes to store a value.
ProductID is a surrogate key
A primary key like our ProductId is what’s known as a surrogate key. It’s basically a key created specifically because it’s easier than using any natural keys. Of course, a natural key is something that naturally uniquely identifies an entity, like a Social Security Number or a VIN number.
If we had an Employees table, for example, with a surrogate key that is an EmplID column, and still had a SSN column, that SSN column can be referred to as a candidate key. A candidate key is a column we recognize should have unique, non-NULL values, but it’s not labeled as the primary key because of reasons already discussed (large data type, data shifting for new and updated rows)
In summary, a surrogate key made up with an INT data type and the IDENTITY property makes for an excellent primary key column!
5. The 6 rules you should know about SQL Server primary keys
We’ll finish this tutorial with a handful of rules you need to remember when working with SQL Server primary key constraints. Some of these rules we have discussed, but other’s we have not.
1. A SQL Server primary key column cannot contain duplicate values
No two rows can contain the same value in a primary key column. This goes back to relational database theory. In order for a table to be considered relational, all rows must be unique!
2. A table can only have one primary key constraint
This is one of those rules you need to remember. I think this ties back to the fact that a clustered index is automatically created when you create a primary key constraint. Data on disk can only be ordered in one way, which means we can only have one clustered index on a table. Ergo, we can only have one primary key constraint on a table!
3. A primary key column cannot contain any NULL values
This is yet another thing to remember, and it deals with relational database theory. Primary key columns must contain non-NULL values.
4. A unique key constraint is different from a primary key constraint
A unique key constraint makes sure that all the values in it’s column are unique. It’s great if you want a column to always contain unique values, but you don’t necessarily want to set that column as the primary key. For example, it would be great to set a unique constraint on a SSN column.
Some of the rules that apply to primary key constraints do not apply to unique key constraints. Unique key constraints differ from primary key constraints in two ways:
- A unique key column can contain one (and only one) NULL value.
- You can have more than one unique key constraint on a table. You can add two or three (or more!) unique constraints to columns in a table if you want to.
Check out the full tutorial on unique constraints to learn more:
SQL Server Unique Index: Everything you need to know
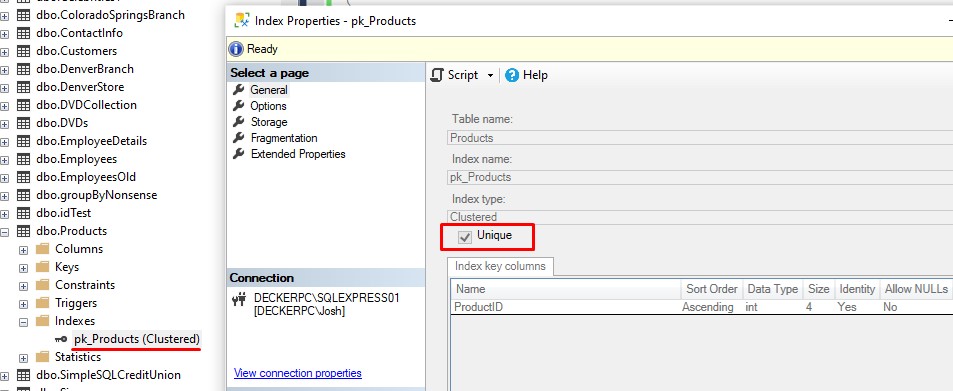
5. The clustered index will be labeled as unique to enforce the uniqueness of the values in the column.
If you look at the properties of the index that was made when the primary key constraint was created, it will be labeled as unique. Here’s our clustered index created from our primary key constraint:
6. You can add a primary key constraint to an already-existing table by using the ALTER TABLE statement
Let’s drop the Products table and re-create it without a primary key constraint:
DROP TABLE Products CREATE TABLE Products ( ProductID INT, ProductName VARCHAR(20), Price DECIMAL(5,2), )
Ok, so let’s say we meant to add a PRIMARY KEY constraint to the ProductID column.
First, we need to remember one of the rules of primary key constraints: It cannot contain NULL values.
This means we first need to label the ProductID column as NOT NULL. That’s easy enough to do with an ALTER TABLE….ALTER COLUMN statement:
ALTER TABLE Products ALTER COLUMN ProductID INT NOT NULL
Ok, so now that the column follows the rules for primary key constraints, we can run another ALTER TABLE statement to add the PRIMARY KEY constraint:
ALTER TABLE Products ADD CONSTRAINT pk_Products PRIMARY KEY(ProductID)
So we use the ADD CONSTRAINT keywords, followed by the name we want to give the constraint, followed by the kind of constraint, followed by the column(s) we want to be in the primary key constraint.
Easy peasy!
Next Steps:
Leave a comment if you found this tutorial helpful!
If you found this tutorial helpful, make sure you…
Download your FREE SQL Server Constraints Ebook!
This FREE Ebook contains absolutely everything you need to know about all the different constraints available to us in Microsoft SQL Server, including:
- Primary Key constraints
- Foreign Key constraints
- Default constraints
- Check constraints
- Unique constraints
Everything found in this tutorial is thoroughly discussed in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Now that you know a thing or two about the Primary Key constraint, you should definitely check out the beloved cousin of the Primary Key constraint: The Foreign Key Constraint.
Check out the full tutorial here:
SQL Server Foreign Key: Everything you need to know
I also touched on the difference between a unique constraint and a primary key constraint. While they are similar, there are some slight differences you need to know. Learn more about unique constraints by reading my full tutorial:
SQL Server Unique Index: Everything you need to know
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, or if you are struggling with a different topic related to SQL Server, I’d be happy to discuss it. Leave a comment or visit my contact page and send me an email!



What an article! You have outdone yourself once again Josh. Wouldn’t it be easier if we can add a constraint at the table level as CONSTRAINT PRIMARY KEY AS constraint_name? I’ll make sure to recommend your papers to everybody in the process of learning SQL!
Thanks for the compliment, Charles! Well we need to associate the PRIMARY KEY constraint with a column. That is how SQL Server knows to order the content of the table on disk. And if we guarantee values in a specific column are unique, we can say every row is unique.