

If you had to explain what a B-Tree is and how it works, could you do it?
I mean, you know it’s a thing in SQL Server, and it is part of indexes (…somehow), but do you really know what it is?
Wood you beleaf me if I told you the B-Tree is the root of our query performance?

Understanding the B-Tree is a very important part of understanding Clustered and Nonclustered indexes and how they can help our queries perform much faster.
If you are you just starting out, and need a quick rundown on Clustered and Nonclustered indexes, I got you:
-
Clustered Indexes: The Ultimate Guide for the Complete Beginner
-
Nonclustered Indexes: The Ultimate Guide for the Complete Beginner
Also, you’ll probably find the following FREE Ebook helpful:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
In this tutorial, we will demystify the B-Tree, and show you exactly how it works and how it helps our queries perform better.
We will discuss just these three topics:
- What is the B-Tree?
- How does the B-Tree work?
- Tips, tricks and links.
Might as well start from the tree top:
1. What is the B-Tree?
The Balanced-Tree is a data structure used with Clustered and Nonclustered indexes to make data retrieval faster and easier.
In our Clustered index tutorial, we learned how a Clustered index relies on the B-tree to find data a query asks for, in an organized and reliable way.
Without the B-tree, SQL Server would need to manually locate data on disk, which would be much more difficult. It would be like trying to find a specific DVD in a pile of DVD’s (kinda like those bins they have at WalMart, right?).
2. How does the B-Tree work?
Ok, so you didn’t open this tutorial for a vocabulary lesson. Let’s get down to business.
To demonstrate the B-Tree, the first thing we need to do is create a very simple table called Students. Here’s the SQL statement to create that table:
CREATE TABLE Students ( LastName VARCHAR(15), FirstName VARCHAR(15), StudentID INT IDENTITY(100,5) )
Notice we used the IDENTITY property on the StudentID column, so we don’t need to worry about typing a new StudentID every time we want to insert a row. I have a full tutorial on the IDENTITY property here: The IDENTITY Property: Everything you need to know.
Ok, now let’s add a clustered index on the LastName column:
CREATE CLUSTERED INDEX idx_LastName on Students(LastName)
Now, let’s add a few rows to the table:
INSERT INTO Students (LastName, FirstName) VALUES
('Alanzo','Jeff'),
('Carlton','Sara'),
('Bridge','Marla'),
('Tanner','Bill')
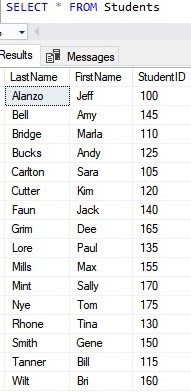
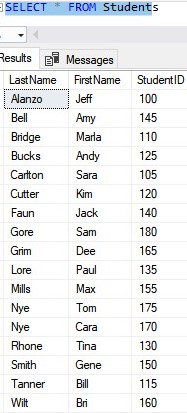
Here’s the SELECT statement:
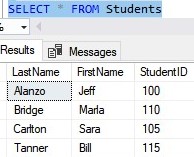
I want you to notice something rather interesting. Notice the SELECT statement presents the data in order by LastName, and not the order in which the rows were added.
Ok, so how do these rows look on the B-Tree right now? Let’s take a look:

Not too complicated. Let’s talk about what we’re looking at.
The blue box symbolizes something called a data page (AKA a node). When data is stored on a hard disk, it is actually stored in nodes like this. A hard disk contains A TON of nodes to store information.
It’s not too important to know all the inner details of what a data page/node is, but it is important to know this one thing:
- A node has a finite size.
A node can only hold so many rows. In my example, notice we’ve pretty much filled the entire node with all 4 of my rows.
(A real-life node can store much more than only 4 rows, but we’re in in pretend land at the moment)
What if we wanted to add a new row to our table? Let’s go ahead and do that:
INSERT INTO Students (LastName, FirstName)
VALUES
('Cutter','Kim')
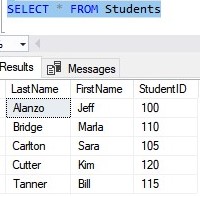
That was easy, but what does the B-tree look like now? Answer:
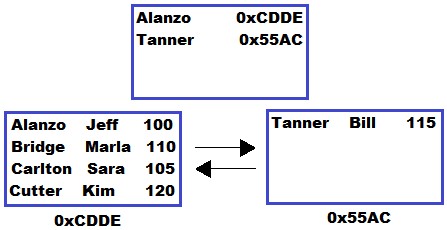
I know: “What the f***“. I got you, let’s break it down.
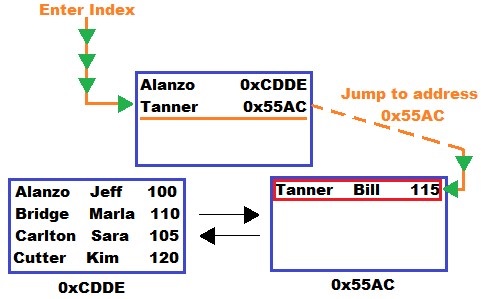
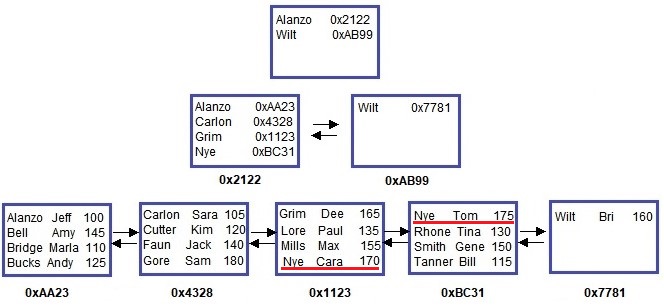
We need to start with some terminology. That top node is called the root node. The two nodes underneath that are called leaf nodes. Those leaf nodes are what contain the actual table data (the LastName, FirstName, and StudentID all together).
You see the weird alpha-numeric strings underneath each leaf node? That’s the address of the leaf node.
You see those arrows between the two leaf nodes? Those symbolize how the two leaf nodes are connected through something called a doubly-linked list. So node 0xCDDE knows how to get to node 0x55AC, and node 0x55AC know how to get to node 0xCDDE. They are connected in each direction to one another.
Here’s another helpful diagram to identify everything:
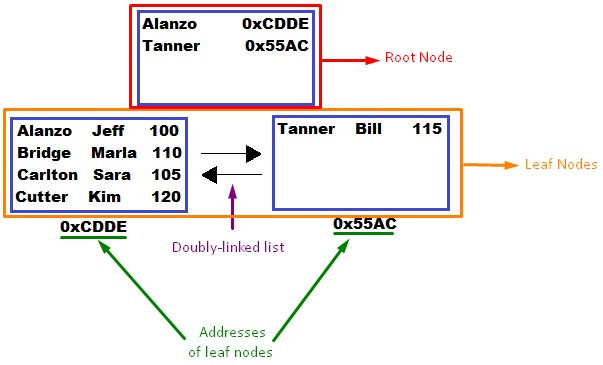
All the blue boxes are still called nodes, and all nodes can still only hold up to 4 items (in pretend land). That fact hasn’t changed.
What has changed, however, is the content of the nodes.
Understanding the information stored in nodes
Let’s think about the content in the root node. Each line in this root node contains two pieces of information:
- The address of the leaf node it points to.
- The minimum key value in the leaf node to which it points.
So for example, the first line in the root node points to the node at address 0xCDDE. What’s the minimum (or first) key value in that node?: Alanzo.
To explain those two things a bit better, it would be best to show you how SQL Server looks through this B-tree to get the data it needs. Say we write the following query:
SELECT * FROM Students WHERE LastName = 'Carlton'
So this query is basically looking for everything we have for the person with the last name ‘Carlton’. This information here:
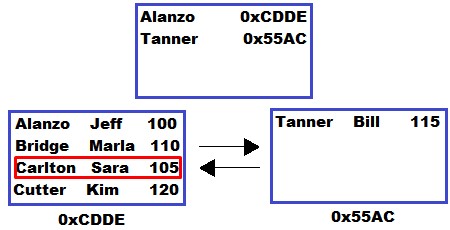
SQL Server is basically going to walk through the B-tree to get to this information.
It starts at the root node (which is the entry point of the index), and looks at each key value. Once it see’s a key value that is greater than the key value we are looking for, it stops looking through the root node.
For example, the first line in the root node has the key ‘Alanzo‘. Alphabetically, this is less than the key value we are looking for (which again is ‘Carlton‘).
So, since ‘Alanzo’ is less than the value we want, SQL Server keeps going down the list.
The next value in the root node list is ‘Tanner‘.
This value IS greater than the value we are looking for.
So at that point, SQL Server stops looking through the root node. It now knows the value we want must be somewhere in the leaf node starting with the name ‘Alanzo’.
(Why does it know the value we want must be somewhere in the leaf node starting with the name ‘Alanzo‘? Because remember, each key value in the root node represents the minimum key value of the leaf node to which it points. Alphabetically, we know ‘Alanzo’ could never come after ‘Tanner’).
Ok, so we know we need to look through the node starting with ‘Alanzo‘. But where is that node? What’s the address of that node?
Duh, it’s the other piece of information stored in the root node. It looks like the node starting with ‘Alanzo‘ is at address 0xCDDE:
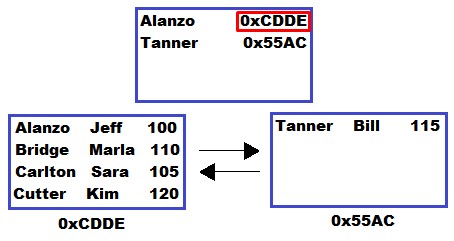
SQL Server knows where to go next: Address 0xCDDE. Once it’s at that node, it goes down the list of items in the node, starting from the top, until it finds the data we’re looking for.
Here is an awesome diagram to show you how SQL Server walks through the B-tree:
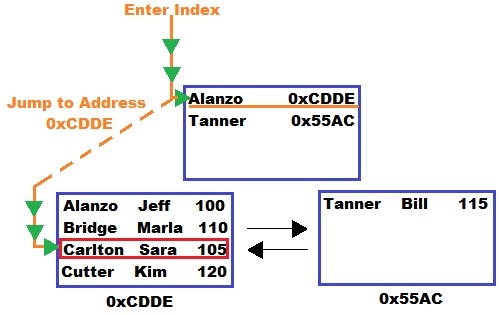
If we were looking for the last name ‘Tanner‘ instead, the walk through the B-tree would be different, wouldn’t it?
Very cool.
Understanding intermediate nodes
There’s one more scenario we need to talk about. Let’s insert enough rows into our table to fill up all our nodes.
Here’s the insert:
INSERT INTO Students (LastName, FirstName) VALUES
('Bucks','Andy'), ('Rhone','Tina'), ('Lore','Paul'),
('Faun','Jack'), ('Bell','Amy'), ('Smith','Gene'),
('Mills','Max'), ('Wilt','Bri'), ('Grim','Dee'),
('Mint','Sally'), ('Nye','Tom')
Here is what the B-Tree looks like:
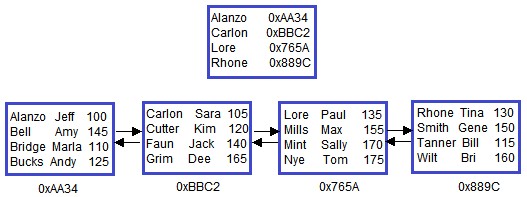
Notice we’re all filled up.
Uh oh. What if we want to add another row?:
INSERT INTO Students (LastName, FirstName) VALUES
('Gore','Sam')
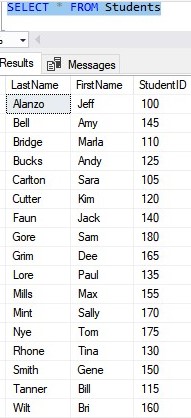
What on earth happens in the B-tree?
Normally if we wanted to add another row, we could just add another leaf node and put our new row data there. The problem is there isn’t enough space in the root node to reference a new leaf node. The root node already has 4 references, which is the max! (in pretend land, that is)
So what does SQL Server do?
It creates another level, called an intermediate level.
Check this out:
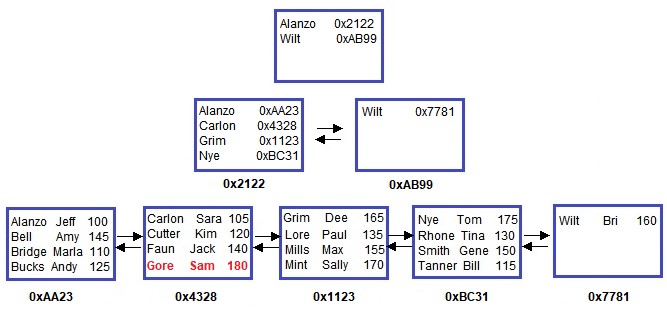
Ok, this is really cool. Let’s start again at the root node. Each line in the root node still contains a reference to another node. However now, the reference is to an intermediate node.
The same rules still apply. Each line in the root node contains two pieces of information:
- The address of the intermediate node it points to.
- The minimum key value in the intermediate node to which it points.
Then, each intermediate node acts like it’s own mini-root node. Similar rules apply to each line in the intermediate nodes. Each line in the intermediate nodes contains two pieces of information:
- The address of the leaf node it points to.
- The minimum key value in the leaf node to which it points.
Folks, this pattern continues as needed. Once we fill all nodes in our B-tree, SQL Server will need to add another intermediate level to make more room. Notice suddenly we have TONS of room to add more rows.
In real life, I’ve heard that most B-trees never need more than 4 or 5 levels total. We’re talking about potentially millions of rows in the B-tree. Maybe that gives you an idea of how much data our nodes can actually hold in real life.
Pop Quiz: Using the diagram above, figure out the path SQL will take to get all the information for our student Gene Smith.
Ready. Set. Go.
…….
Ok, here is the path SQL Server takes to get to Gene Smith:
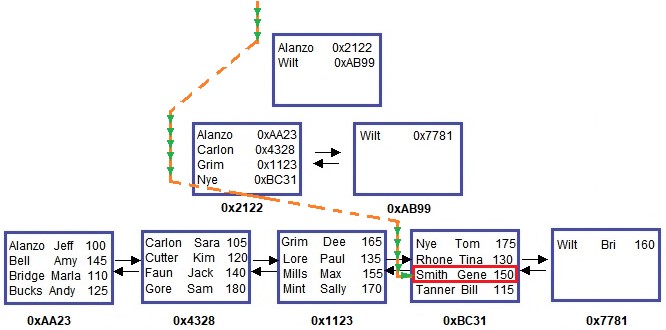
Well done.
Nodes are linked using a doubly linked list
The last thing I want to demonstrate is how SQL Server will use the doubly-linked list between nodes.
This whole time, we’ve been doing singleton lookups, where we are looking for a single value. Let’s write a query that does a range lookup using a wildcard character, where we return a range of values:
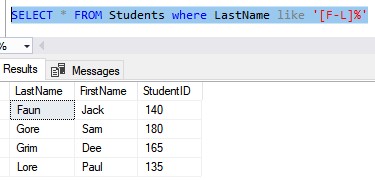
This query looks for any LastName starting with the letters ‘F‘ through ‘L‘.
SQL Server will use the B-tree, and find the first row that satisfies this filter. To find the rest of the rows that satisfy this filter, it will need to use the doubly-linked list:
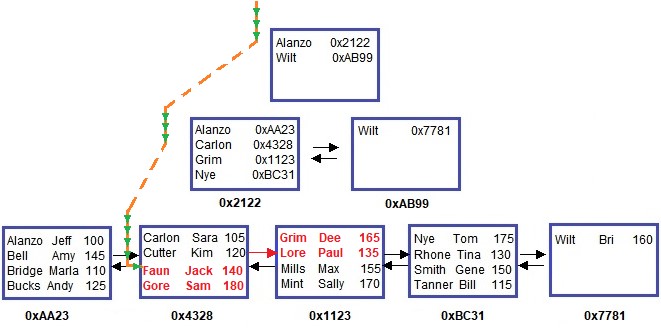
Notice the red arrow, pointing to the next node. Like I said earlier, the leaf nodes (and also the intermediate nodes) are connected to each other by a doubly-linked list. SQL Server does not need to do another walk-through to get to a different leaf-level node to read more rows. It just uses the doubly-linked list instead!
3. Tips, tricks and links.
Here are a list of tips and tricks you should know about the B-tree and indexes.
Tip #1: You should define your indexes as UNIQUE if your index key contains unique values.
Having an index labeled as UNIQUE helps SQL Server from needing to look through other leaf-level nodes for other matching rows.
For example, let’s change the name of student # 170:
UPDATE Students SET LastName = 'Nye', FirstName = 'Cara' WHERE StudentID = 170
Notice now, we have two people with the last name ‘Nye‘. Here is what the B-tree looks like:
Ok, so if we want to look for anyone with the last name ‘Nye‘, SQL Server will walk the path like this:
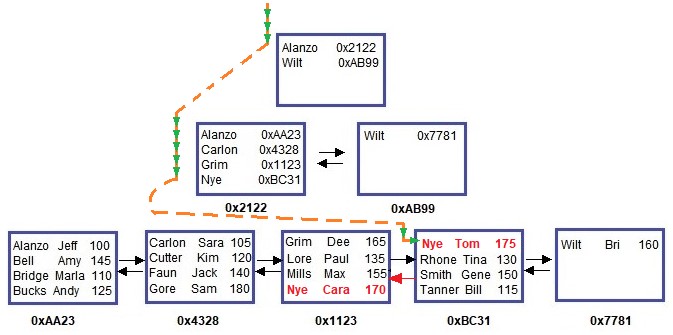
Since our Student ‘Tom Nye‘ is the first in his node, SQL Server needs to use the doubly-linked list and look in the previous node for any other ‘Nye’ that might exist at the end of that node.
It just so happens there is, in fact, another ‘Nye’ at the end of the previous node.
But folks, even if there wasn’t another ‘Nye’ in the previous node, SQL Server is still going to check. Since we did NOT label our index as UNIQUE, SQL Server needs to see if there are other matching rows at the end of the previous node.
In our simple example, we probably want to leave the index as non-unique. Two people can certainly have the same last name, which means we want to allow SQL Server to do this kind of check.
But what if we know, for sure, our key values are unique? In that case, SQL Server would be wasting it’s time looking in the previous node for other matching rows.
A good example would be setting up an index on a Primary Key column. Primary Key values are always unique (that’s why it’s the primary key, right?). In that case, it would be ideal to label the index as unique. In fact, if you set a clustered index on a primary key column, SQL Server will automatically make the index unique.
Tip #2: A B-tree is created for both clustered and nonclustered indexes.
In this entire tutorial, we have been looking at the B-tree for a clustered index, but understand a nonclustered index will also use a B-tree.
Links
There is an awesome book called Pro SQL Server Internals that discusses everything you need to know about indexes and the B-tree, as well as many other internal tools and concepts involved with Microsoft SQL Server. The book helped me out tremendously when I was trying to understand indexes. You definitely won’t regret owning this book, trust me. Get it today!

Next Steps:
Leave a comment if you found this tutorial helpful!
Also, make sure you download your FREE Ebook:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Make sure you check out my full tutorials on Clustered and Nonclustered indexes, found here:
-
Clustered Indexes: The Ultimate Guide for the Complete Beginner
-
Nonclustered Indexes: The Ultimate Guide for the Complete Beginner
Indexes are a HUGE PART of database development and administration, so you need to make sure you understand what they are and how they work.
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, please leave a comment. Or better yet, send me an email!



Thank you so much, your explanation is AMAZING !
This is the best tutorial i hve ever read, thank sooooo much. Very clear and so simple to understand.
You are the best
Glad it helped! Let me know if you need help with anything else. Email me at SimpleSQLTutorials@gmail.com.