

There are many very helpful querying tools available to us in Microsoft SQL Server. One of the more complicated querying tools to understand is correlated subqueries.
If you are new to SQL Server, I would understand if you simply don’t “get” correlated subqueries. They are a bit strange to wrap your head around.
If you’re struggling to understand how correlated subqueries work, you’ve come to the right place!
In this very brief tutorial, we’ll discuss what a correlated subquery is and how it can help us pull meaningful data from our databases.
We’ll discuss these topics:
- What is a correlated subquery?
- It helps to understand noncorrelated subqueries first
- Examples of correlated subqueries and how they work
- Tips and tricks
Make sure you download the following FREE GUIDE:
FREE 1-page Simple SQL Cheat Sheet on Correlated Subqueries!
This guide provides a summary of everything you need to know about correlated subqueries in SQL Server. It will be an excellent resource to have as you advance your career in the data science field. Get it today!
Let’s take it from the top.
1. What is a correlated subquery?
A correlated subquery is an inner query that references columns from the outer query when executing. The inner query relies on data from the outer query, which means the inner query cannot run independently.
Correlated subqueries can be tricky to understand conceptually. Before we can understand how correlated subqueries work, we should take a step back and understand what a noncorrelated subquery is first.
2. It helps if you understand noncorrelated subqueries first
Noncorrelated subqueries are also known as self-contained subqueries. Microsoft refers to them as self-contained subqueries, so I will also refer to them as that henceforth.
First, let’s take a look at some data. Take a look at the following Customers and Orders tables:
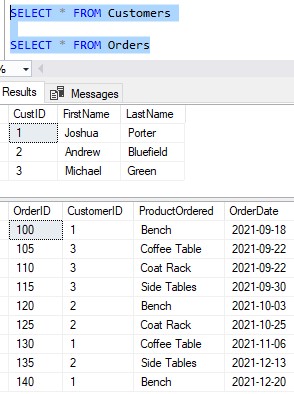
If you want to create this data in your environment to follow along (recommended), here are the statements:
CREATE TABLE Customers(
CustID int IDENTITY(1,1) NOT NULL,
FirstName varchar(15) NULL,
LastName varchar(15) NULL
)
CREATE TABLE Orders(
OrderID int IDENTITY(100,5) NOT NULL,
CustomerID INT NOT NULL,
ProductOrdered varchar(50) NULL,
OrderDate date NULL
)
INSERT INTO Customers (FirstName, LastName)
VALUES
('Joshua', 'Porter'),
('Andrew', 'Bluefield'),
('Michael', 'Green')
INSERT INTO Orders (CustomerID, ProductOrdered, OrderDate)
VALUES
(1, 'Bench', '2021-09-18'),
(3, 'Coffee Table', '2021-09-22'),
(3, 'Coat Rack', '2021-09-22'),
(3, 'Side Tables', '2021-09-30'),
(2, 'Bench', '2021-10-03'),
(2, 'Coat Rack', '2021-10-25'),
(1, 'Coffee Table', '2021-11-06'),
(2, 'Side Tables', '2021-12-13'),
(1, 'Bench', '2021-12-20')
Ok, so let’s write a very simple query that uses a self-contained subquery. This query basically tells us the details for the most recent order for a specific customer:
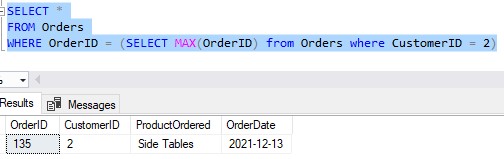
The inner query (which is SELECT MAX(OrderID) from Orders where CustomerID = 2 ) tells us the order with the highest OrderID for Customer # 2. This ought to be the most recent Order placed by that customer. We can consult the Orders table to double check (I have, and it looks correct).
Once we have the OrderID, we use that value as input for the outer query. The WHERE clause in the outer query is looking for a specific OrderID value, which is provided by the inner query.
What’s easy about this query is that we can highlight the inner query and execute just that query to see what it returns:
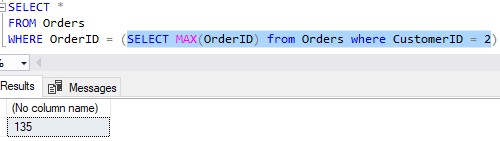
This can be helpful for troubleshooting purposes.
I want to point out something that you might have noticed. Both the inner and outer queries both query the same table: The Orders table. This can be a common thing when writing correlated or self-contained subqueries.
3. Examples of correlated subqueries and how they work
Ok, now that you understand self-contained subqueries, let’s think about how we could alter the query to be correlated.
The last example showed us details for one specific customer. What if you wanted to see details for all customers? That is, you want to see order information for the most recent order for each customer.
If we look at the Orders table, let’s see if we can simply spot what those orders will be. There are only 3 customers, so it should be easy to spot what the most recent order is for each:
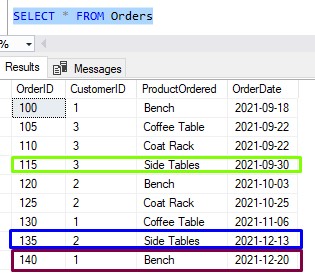
That was easy enough
- For Customer # 1, it looks like his most recent order was Order # 140
- For Customer # 2, it looks like his most recent order was Order # 135
- Finally, for Customer # 3, it looks like his most recent order was Order # 115
Awesome. So if we want to write a query to pull highest Order info for each customer, we expect those three rows to show up.
Here is the query, then we’ll talk about it (the actual correlated subquery is highlighted in red):
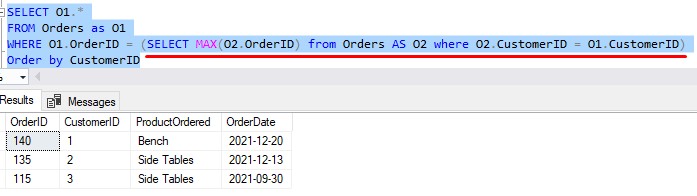
First of all, the result set checks out, which is great. But let’s see if we can understand how this thing works.
Understanding how correlated subqueries work
As mentioned in the definition in Topic # 1, a correlated subquery contains a reference to a column from the outer query. In this example, the column we’re referencing from the outer query is O1.CustomerID.
When running a correlated subquery, SQL Server essentially goes down the list of rows in the outer result set one at a time, passing the needed information to the subquery. Again, in our case, that’s the CustomerID value.
So, let’s go down the list of orders like SQL Server will do. When we’re going down each row in the outer Orders result set, we need to note two important details: The CustomerID and the OrderID of the row.
Here we go, the first row in the outer table is this:
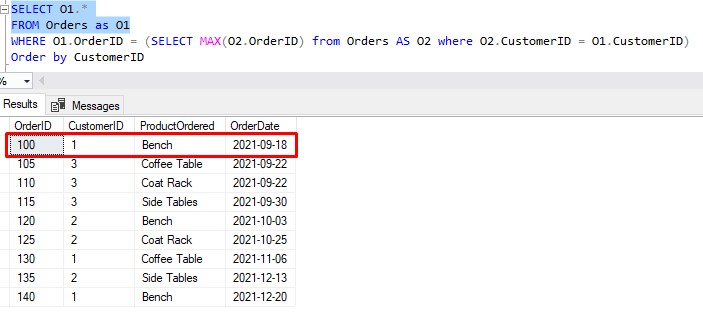
I said we need to note two important details, the CustomerID and OrderID of this row. Those values are 1 and 100 respectively.
This CustomerID value of 1 is what get’s passed to the subquery, as the O1.CustomerID value. We can hard-code that value into the inner query to do some testing:

That inner query can now be ran by itself, since we’ve basically turned it into a self-contained subquery:
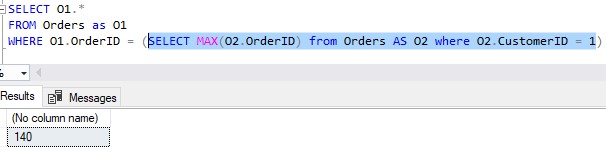
The WHERE clause of the outer query
Now, here’s where we need to remember the second value we said we had to note about the outer row: The OrderID. The OrderID of the row we’re currently processing is 100.
Is 100 equal to what was returned by the inner query (140)?
Nope! Therefore, that first row is NOT returned in the final result set.
Folks, this process is repeated for all rows in the outer result set. We pass the CustomerID to the inner query, then see if it’s returned value is equal to the OrderID of the row we’re on. If not, the row is discarded. If so, the row is returned in the final result set.
Going on down the line
Let’s keep going down the line to find a row that will get returned in the final result set. Here is the next row in the outer result set:
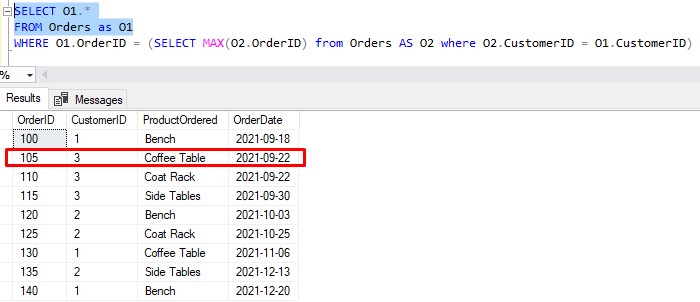
Note the key columns: CustomerID is 3, OrderID is 105. Plug in the CustomerID value into the inner query and execute:
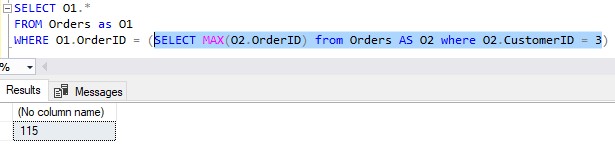
Is 105 equal to 115? Let me check…
Nope! So this row also won’t be in the final result set.
Now the next row:
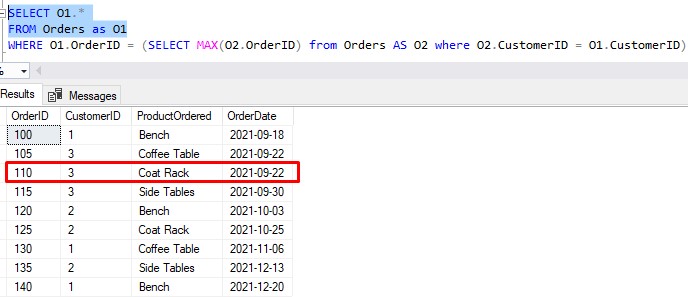
We already know what the inner query will return when using this CustomerID value of 3. We just did that for the previous row, and the returned OrderID value was 115. Is 110 equal to 115? Of course not, so this row is also discarded.
Finally, we get to a promising row:
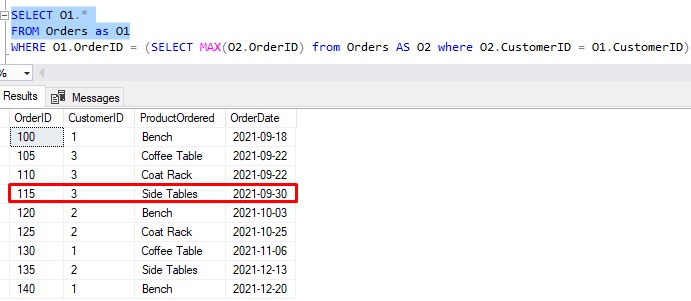
Again, we’re working with a CustomerID value of 3. We already know the inner query will return 115 when using this O1.CustomerID value. So (say it with me), is 115 equal to 115?
YES!
This row will be returned in the final result set. Again folks, this process is repeated for all rows in the outer result set. If there is a row that you think should be in the final result set, but it’s not, you should plug in the value of the correlated column into the subquery to see what the subquery will return. Then compare that value to what is getting filtered in your WHERE clause.
That’s the best way to understand and troubleshoot correlated subqueries. Just turn them into self-contained subqueries and see what get’s returned!
4. Tips and tricks
Here are just a few tips to know when working with correlated subqueries:
Tip # 1: Sometimes you can use a different query to return the same result set
In SQL Server, you’ll learn there is more than one way to skin a cat.
(By the way, what kind of sick, twisted f*ck came up with that saying?)
We can use a GROUP BY inner query that ultimately gives us the same result set:
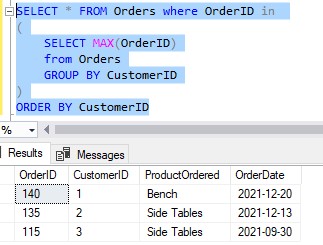
I just want to point that that you should know multiple ways to generate the same result set. Sometimes one query might perform better than another, or sometimes one query is simply easier to read than another. It’s good to know many querying tools.
Tip # 2: Remember, the easiest way to troubleshoot correlated subqueries is to turn them into self-contained subqueries
We already discussed this tip, but it’s worth repeating. The easiest way to debug a correlated subquery is to temporarily hard-code the correlated column value into your subquery. That way, you can run the inner query independently to see what gets returned. Then, compare that to what you need in the WHERE clause of your outer query.
Next Steps:
Leave a comment if you found this tutorial on correlated subqueries helpful!
If you found this tutorial helpful, you should definitely download the following FREE GUIDE:
FREE 1-page Simple SQL Cheat Sheet on Correlated Subqueries!
This guide provides a summary of everything you need to know about correlated subqueries in SQL Server. It will be an excellent resource to have as you advance your career in the data science field. Get it today!
Another excellent querying tool you should know is the EXISTS predicate. It works very similarly to how a correlated subquery works.
Do you know how EXISTS works? Click the link to find out!
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, leave a comment. Or better yet, send me an email!


