
In this tutorial, we will discuss a common characteristic of nonclustered indexes: INCLUDED columns.
If you missed the full discussion about nonclustered indexes, I suggest you read that first. Check it out here:
Nonclustered Indexes: The Ultimate Guide for the Complete Beginner
In this tutorial, we will answer the following questions:
- What is an INCLUDED column in an index?
- How does an INCLUDED column help our queries perform faster?
- What is the syntax for INCLUDING columns in an index?
- How to see what columns are already INCLUDED in an existing nonclustered index
- What is the downside to using INCLUDED columns?
- How to alter the list of INCLUDED columns, and other tips, tricks and links
If you are just starting out with SQL Server, and are trying to understand what indexes are, you will probably find the following FREE Ebook very helpful:
FREE Sql Server Indexes Ebook!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Let’s get started:
1. What is an INCLUDED column in an index?
If a column is INCLUDED in a nonclustered index, a copy of that column data will be included next to the nonclustered index key value in the data structure of the nonclustered index. This prevents SQL Server from needing to do a lookup of that included column’s data.
If that sounded like another language to you, it’s ok. We’re going to break it down and give you a great analogy.
2. How does an INCLUDED column help our queries perform faster?
To fully understand INCLUDED columns, it is worth doing a quick review of nonclustered indexes. For a full review, be sure to check out the full tutorial on the topic here: Nonclustered Indexes: The Ultimate Guide for the Complete Beginner.
Nonclustered indexes store a copy of a column’s data in a data structure known as a B-Tree. For nonclustered indexes, this copied data is stored in memory. The column who’s data we’re copying is known as the nonclustered index key.
In the nonclustered index data structure, each entry stores not only a copy of the column’s data, but also a pointer to the clustered index key for that entry.
In the tutorial about nonclustered indexes, I gave an analogy of my book collection, where I labeled each book with a number that represents the clustered index key value:

Again, this represents the clustered index, not the nonclustered index.
The concept of INCLUDED columns applies to nonclustered indexes
The following piece of paper represents a nonclustered index, where my nonclustered index key column is the Title of each book:

Notice this list is showing my books in ascending order by Title. Each book has a pointer to the corresponding clustered index key value.
This pointer is what helps us know where to look if we need more information about the row.
That last sentence is where we begin to understand the idea behind an INCLUDED column. I’ll repeat it: The pointer is what helps us know where to look if we need more information about the row.
Say we’re looking at our list on our piece of paper, and we want to know if we have a book called “Pro SQL Internals“.
(Great book by the way if you want to learn everything there is to know about indexes)

We can easily search through our list because the Titles of the books are arranged in alphabetical order. If we look through the list, we see that I do, in fact, own “Pro SQL Internals”.
Great! But what if we wanted to know the Author of that book? Again, all we’re looking at right now is the piece of paper (which is the nonclustered index).
The Author information is not there!
Since the Author information is not written on my piece of paper, we will need to use the pointer for that entry (which appears to be 7), use it to find BookID 7 in our collection, pull it out, and see who the Author is.
That is too much work for me. I have things to do.
When I wrote down the Titles of each book on my piece of paper, I should have also included the Author of each book. That way, I wouldn’t need to do all that extra work. Basically, like so:

Superb! Now if we want to find a book, and it’s author, we can find it very easily!
Congratulations, now you understand the idea behind an INCLUDED column in a nonclustered index.
INCLUDED columns make data retrieval faster
An INCLUDED column will store a copy of it’s data next to the index key column value in the data structure of the nonclustered index. That way, SQL Server doesn’t need to look anywhere but the nonclustered index data structure to get the column values it needs!
Taking this back to SQL for a minute, let’s say we did the following SQL Statement before I included the Author column in my nonclustered index.
SELECT Author FROM Books WHERE Title = 'Pro SQL Server Internals'
Sure, the Title will be found easily using the nonclustered index. But the query doesn’t ask for only the Title column, does it. It also asks for the Author.
Since the Author column is not included in the nonclustered index, SQL will need to perform a Key lookup to get that information.
But if I INCLUDE the Author column as part of the nonclustered index, SQL will not need to do that lookup! All the information it needs is in the nonclustered index!
3. What is the syntax for INCLUDING columns in an index?
It’s simple
CREATE INDEX index_name ON table_name(column_name) INCLUDE (included_column_name)
So if we want to create the nonclustered index with an INCLUDED column like we have been discussing, it would look like this:
CREATE INDEX idx_Title ON Books(Title) INCLUDE(Author)
4. How to see what columns are already INCLUDED in an existing nonclustered index
The easiest way is to look at the properties of the index via the SQL Server Object Explorer. In the Object Explorer, you would expand the database in question, then the table in question, then the Indexes folder. There you will see the list of indexes for that table. Here’s an example:
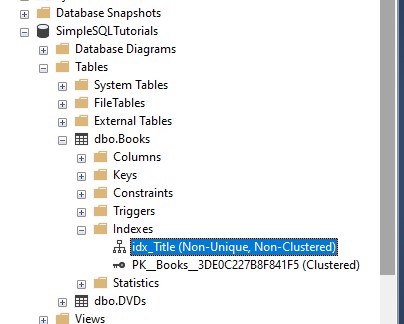
Then, just right click on the Index and choose Properties. You will see a tab in the properties that shows the ‘Included Columns‘:
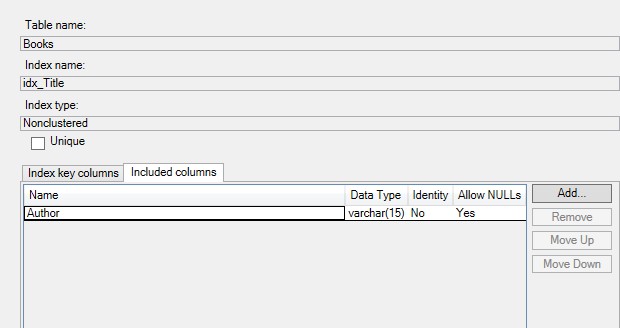
5. What is the downside to using INCLUDED columns?
You might be thinking to yourself, “Well heck, why don’t I just include ALL columns so SQL Server never needs to perform a lookup EVER AGAIN!”
Whenever we include a column or columns, we are duplicating the data. Think about it. Now, I need to maintain the Author in two places. If we change the Author on my physical book, then we also need to change it on my piece of paper.
(And yes, I know I can’t just change the Author on the book, but we’re in pretend land at the moment. In SQL Server, however, you can absolutely change the Author if you needed to)
So, in SQL Server, if we need to update the Author of a book, if that Author is INCLUDED in a nonclustered index, SQL Server will need to update the information there too, behind the scenes.
(But just to be clear, SQL Server will handle that side of it. You don’t need to write two separate UPDATE statements)
INCLUDED columns make the task of inserting, updating, or deleting data slower.
The same idea is true for not only updating data, but also adding or deleting data. If you add a new book, SQL will need to add a copy of the Author to the nonclustered index (as well as the Title, of course). This takes time and uses space.
If you delete a book, SQL will need to make sure it gets removed from the nonclustered index as well. Again, this takes time.
Also, when you duplicate data, you take up memory that could be used for something else. Remember, a server has a finite amount of memory.
6. How to alter the list of INCLUDED columns, and other tips, tricks and links
Here are some helpful things to know about INCLUDED columns:
Tip # 1: Altering the list of INCLUDED columns is tricky
To alter the list of INCLUDED columns, you need to actually drop the old index and re-create the index with the new list of included columns. To drop an index, use the DROP INDEX statement:
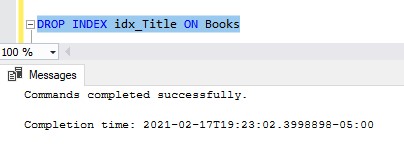
Then, you can re-create the index with your new INCLUDED column list:
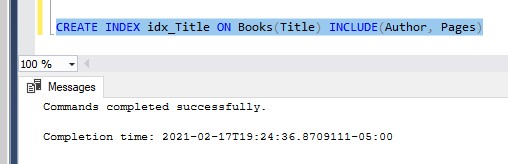
Tip # 2: You cannot INCLUDE columns when defining the index in a CREATE TABLE statement
In the Nonclustered Index tutorial, I mentioned how you can create a nonclustered index inline with the definition of the column, in your CREATE TABLE statement. Here is what I mean:
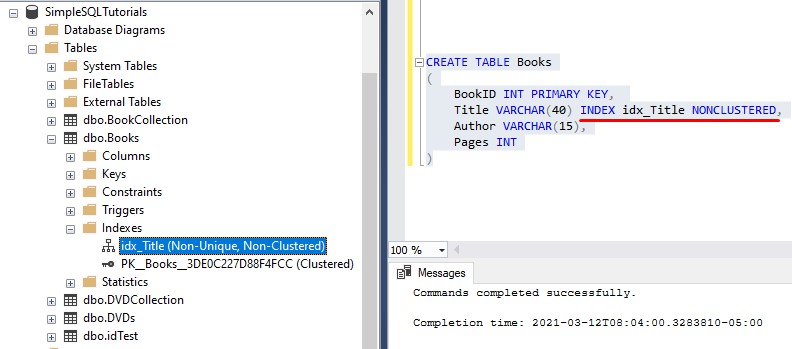
You should know you cannot INCLUDE columns to your nonclustered index when it is defined in this way. If you try, you will get an error message:
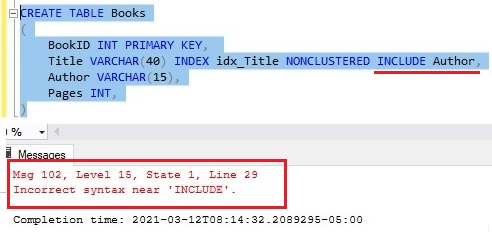
There is a way to define the index in the CREATE TABLE statement after all the columns:
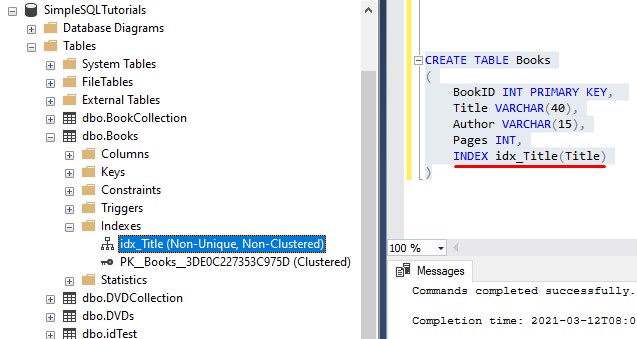
But still, you will get the same error message if you try to INCLUDE other columns to your nonclustered index:
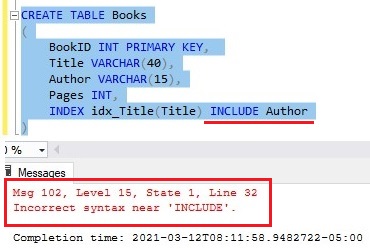
Maybe this will be a feature in Microsoft SQL Server in the future, but for now, it’s not allowed!
Tip # 3: You can INCLUDE more than one column in a nonclustered index
If you want to INCLUDE more than one column, you would separate each column in your INCLUDE list using a comma. But remember, for every column you include, you are duplicating data, which we try to keep at a minimum.
Tip # 4: You can only INCLUDE columns to a nonclustered index
The concept of including columns does not apply to clustered indexes.
Tip # 5: INCLUDED columns can help keep SQL Server from abandoning the use of a nonclustered index when searching for data
If SQL Server is analyzing a query, and determines it will need to do several key lookups (maybe because there aren’t many INCLUDED columns), SQL Server might just abandon the use of the nonclustered index to get the column values it needs.
Basically if SQL Server see’s it will need to do a ton of lookups, it will just say “screw that”, and just get all the information it needs from the clustered index, since all the data is there anyway.
Sure, it will need to scan through that entire clustered index, but that might be faster than doing a bunch of lookups (gnomesayin?)
So INCLUDED columns are a great way to help keep SQL Server from abandoning the use of a nonclustered index.
Links:
As mentioned earlier, there is a great book called Pro SQL Server Internals that explains absolutely everything you need to know about indexes, including how INCLUDED columns work. You should definitely get this book if you want to expand your SQL Server knowledge. This book helped me out tremendously when I was learning about SQL Server indexes, and I reference it all the time now. You won’t regret owning this book, trust me.
Next Steps:
Leave a comment if you found this tutorial helpful!
Also, make sure you download your FREE Ebook:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Refresh yourself on how clustered and nonclustered indexes can help you write efficient queries. Here are some links:
-
Clustered Indexes: The Ultimate Guide for the Complete Beginner
-
Nonclustered Indexes: The Ultimate Guide for the Complete Beginner
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, leave me a comment. Or better yet, send me an email!


