

Indexes are extremely important when it comes to writing queries that return data in an efficient way. We not only want to make sure our queries return exactly the information we need, but we also want that information to be returned to us quickly.
In this brief tutorial, we’ll discuss the idea of a covering index in SQL Server. We’ll discuss these topics:
- What is a covering index?
- An analogy to understand covering indexes
- A demonstration of a covering index
- Links
Let’s get into it.
1. What is a covering index?
A covering index is simply a nonclustered index that contains all the data that a particular query is asking for.
If SQL Server can avoid going to disk to gather the data that a query is asking for, and instead get all the data from memory (which is where nonclustered indexes live), then that will be a much faster operation.
In that case, we can say the query is completely covered by the nonclustered index.
When we think about covering indexes, our focus really shouldn’t be on the indexes so much as the queries we are writing. We really should be asking ourselves, “Is this query covered by an index?“.
The data in the nonclustered index may be part of the index key column(s), or perhaps part of the list of columns INCLUDED in the index. Either way, the point is that everything that the query is asking for is contained in the nonclustered index.
At this point, it should go without saying that in order to understand covering indexes, you need to know a thing or two about nonclustered indexes. If you don’t understand nonclustered indexes or INCLUDE columns, check out the following tutorials:
Nonclustered Index in SQL Server: A Beginner’s Guide
SQL Server Index INCLUDE: Explained with Examples
2. An analogy to understand covering indexes
There is a great analogy I always think of when it comes to understanding nonclustered indexes in SQL Server.
Imagine you walk into a bookstore and you’re looking for a specific book with the title “Annihilation“.
We need to think about how books are ordered on the shelf in a bookstore or a library. Books are organized in alphabetical order by author, right?
If we’re looking for a book called “Annihilation“, but we don’t know who wrote it, having books on the shelf in order by author really doesn’t help us. We’re reduced to looking through all the books on the shelf, trying to find one that has the title “Annihilation“, which could take hours.
What if this particular bookstore understands this problem and has a very helpful notebook at the front desk that contains a complete list of books in their inventory in alphabetical order by title. Next to each title is the author who wrote the book.
Using this notebook, we can easily locate our “Annihilation” book, then see who wrote it. Once we know who wrote it, we can find the book on the shelf easily since books are ordered there by author!
Here’s an example of what the notebook might look like:

(Our bookstore doesn’t have many books)
This notebook represents a nonclustered index with an INCLUDE column
This notebook will help you understand the idea of a nonclustered index and how it can be used to cover a query.
Books are ordered in this notebook by a different criterion than how the books are ordered on the shelf. On the shelf, books are ordered by author, but here in our notebook, books are ordered by title.
Conveniently, next to each title is the author who wrote the book and how many pages long the book is. If we want to find our “Annihilation” book, we can easily see who wrote it, then use that information to easily find it on the shelf since books are ordered there by author!
If we weren’t really interested in actually reading the book, but just wanted to know how many pages long the book is, we really don’t even need to leave the notebook, right? That information is already there!
Folks, this is exactly how nonclustered indexes, clustered indexes, and INCLUDE columns work.
- Nonclustered indexes store a reference to the data in a different order than how the data is defined on disk. The different ordering may be useful for locating data quickly for a particular query.
- Each value in the nonclustered index contains a reference to the clustered index key to which is relates. If we need to get more information, we know exactly where to go on disk to get it.
- Storing extra information in the form of an INCLUDED column may make a query that much faster!
3. A demonstration of a covering index
Let’s create some data and work through an example of creating a covering index. We’ll create a Books table and populate it with rows:
CREATE TABLE Books
(
BookID INT IDENTITY(10,5),
Author VARCHAR(30),
Title VARCHAR(50),
Pages SMALLINT,
PublicationYear SMALLINT
)
INSERT INTO Books (Author, Title, Pages, PublicationYear)
VALUES
('Newport','Deep Work', 263, 2016),
('Pressfield','War of Art', 165, 2012),
('Rinella','American Buffalo', 258, 2019),
('Schwarzenegger','Education of a bodybuilder', 256, 1993),
('Thomas','Pragmatic Programmer', 283, 2019),
('Vandermeer','Annihilation', 195, 2014)
Now let’s create a clustered index on the Author column:
CREATE CLUSTERED INDEX idx_Book_Author ON Books(Author)
This clustered index defines how books are to be ordered on disk: By Author.
Cool, now let’s create a nonclustered index on the Title column and INCLUDE the Pages column:
CREATE NONCLUSTERED INDEX idx_Book_Title ON Books(Title) INCLUDE (Pages)
Folks, we just set up a scenario exactly like our notebook. The nonclustered index outlines books by Title, which is different than how they are ordered on disk. This different ordering may be useful for certain queries.
A covered query:
The following query is completely covered by the nonclustered index:
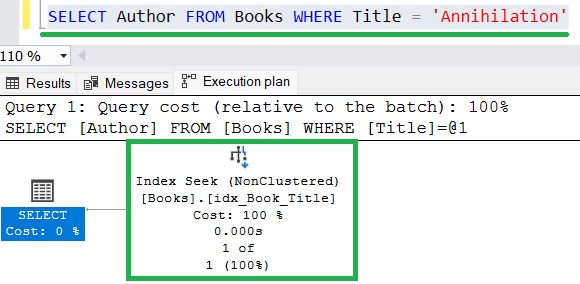
The query is looking for a specific book (“Annihilation“), and it only wants to know the Author of the book. Notice how SQL Server determined that the quickest way to get this information was through the nonclustered index we created. It could locate the book title easily in the nonclustered index data structure, and the Author value is referenced next to that title.
The following query is also completely covered:
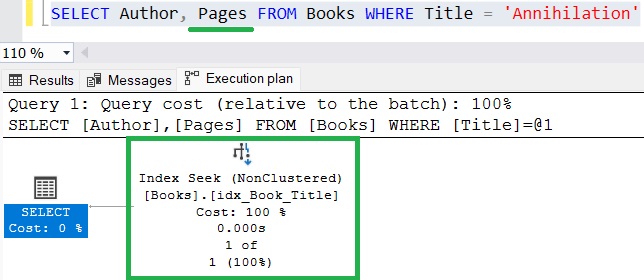
Notice all I added was the Pages column to the column list. The Pages column is INCLUDED in the nonclustered index, which means each book referenced there will also have a copy of the Pages value for that book. Once again, there isn’t a need to leave the nonclustered index!
The following query is NOT covered:
This query, however, is not covered:
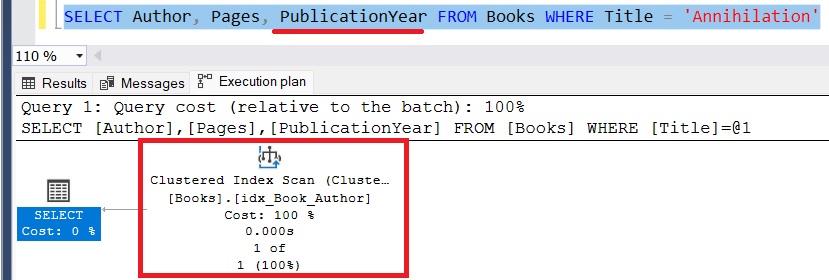
The query is now asking for a value that is not contained in the nonclustered index. Notice SQL Server chose not to use the nonclustered index at all and chose to gather everything from the clustered index, which is on disk.
If we force SQL Server to use the nonclustered index, an interesting thing happens:
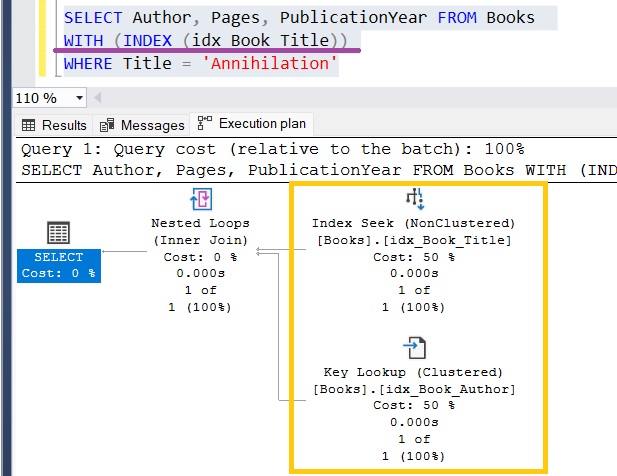
We explicitly tell SQL Server to use the nonclustered index. Unfortunately, this means it will need to look up the value of the PublicationYear since that value is not part of the nonclustered index.
The process of looking up the value is identified by the “Key Lookup” operation we see in the execution plan.
So again, since this lookup needed to happen to gather all the data the query is asking for, this particular query is not covered by the nonclustered index.
In other words, we can say the nonclustered index is not a covering index for this query!
4. Links
You’ll probably find the following FREE Ebook helpful:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional.
In it, we talk in great detail about nonclustered indexes and how to INCLUDE columns. It also discusses a downside to INCLUDE columns that you need to consider before adding them to your nonclustered indexes.
Download the Ebook today!
Next Steps:
Leave a comment if you found this tutorial helpful!
As mentioned earlier, you really need to understand how nonclustered indexes work and the idea of INCLUDE columns to fully understand the idea of a covering index. Check out the full beginner-friendly tutorials to learn more:
Nonclustered Index in SQL Server: A Beginner’s Guide
SQL Server Index INCLUDE: Explained with Examples
Also, while we’re at it, you should understand how clustered indexes work, too. Check it out:
SQL Server Clustered Index: The Ultimate Guide for the Complete Beginner
Indexes are monumental towards writing efficient queries against our databases. Make sure you know how they work and how to create them!
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, or if you are struggling with a different topic related to SQL Server, I’d be happy to discuss it. Leave a comment or visit my contact page and send me an email!


