
When I was first learning how to query and develop databases using T-SQL, I would find myself confused between the different character (aka string) data types available to us.
I would ask myself questions like:
“What’s the difference between CHAR and VARCHAR?“
Or maybe:
“What’s the difference between CHAR and NCHAR?“
And shoot, while we’re at it:
“WHAT’S THE DIFFERENCE BETWEEN VARCHAR AND NVARCHAR?!“
I didn’t really put too much thought into which data type I was using in my tables. I said to myself “Well, it works, so who cares?”
You’re boss cares, and your clients will care. Trust me.
In this tutorial, we are going to demystify the differences between the 4 most common character data types available to us in Microsoft SQL Server.
We’ll cover each character data type:
- The regular character data types
- CHAR
- VARCHAR
- The “Unicode” character data types
- NCHAR
- NVARCHAR
All these character data types are referenced in the following FREE guide:
FREE EBook on SQL Server Data Types!

Definitely download that guide if you want to learn about the most common data types you will encounter as a database professional.
First things first:
1. The regular character data types
What makes CHAR and VARCHAR regular? Well, we just use the word “regular” to mean data types that aren’t Unicode.
You could call them “normal”, or “standard”, if you want. But Microsoft refers the them as “regular“, so I will too.
The first regular character data type to talk about is:
The CHAR data type
This data type should be used when you want to represent character strings that are relatively close in size.
Let’s look at a simple table called WarehouseEmployees:
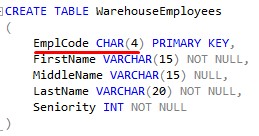
This table holds some very basic information about our Employees.
Notice the EmplCode column. We wanted to give each employee a unique EmplCode to identity them easily.
Ideally, the EmplCode will simply be the initials of the Employee. Here is what our table data looks like:
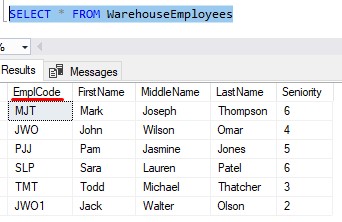
Notice each EmplCode is the initials of the person’s first, middle, and last name.
Cool, so why did I choose to use CHAR for this column, instead of any of the other character data type? And why did I choose a size of 4?
Nearly all the EmplCode values will be the same size: 3 characters
Sure, some people don’t have a middle name, so their EmplCode would only be 2 characters. And in the rare event we have two or more people with exactly the same initials, we might need to use our 4th character to add an extra character to make each EmplCode unique.
Like in the case of Jack Walter Olson. His initials are ‘JWO‘, but we already had an employee with those initials, John Wilson Omar. So to make a unique EmplCode, I just tacked on the number ‘1‘ for Jack.
That brings me to a good point about the size of your character data types:
You should use the smallest size to fit your needs.
Like I said, most people will have 3 character initials, but we need to be prepared for the rare event where 3 isn’t enough. That’s why I gave the column a size of 4.
I don’t think we’ll need more than that.
It’s important to think about these things now while there isn’t much (or any) data in your table, as opposed to later when it will likely be more difficult.
Here’s the final important thing to remember about the CHAR data type:
The CHAR data type will reserve the full size you have given it in memory for every value stored.
Let’s give you an example.
We gave our EmplCode column a size of 4. That means in memory, every value stored for that column will take up 4 bytes, regardless of how much of that is actually used.
(FYI the regular character data types use 1 byte to store 1 character under normal, single-byte encoding)
Take EmplCode ‘PJJ‘. This string is only 3 bytes long, but in memory, it will be stored in a space that is 4 bytes big. So essentially, 1 byte is wasted.
If we even have an EmplCode with just 2 bytes, it will still be stored in a space that is 4 bytes big.
An analogy: A garage for your car
Say you built a two-car garage, but you only own 1 car. In fact, I found a picture of your car:

Your 1 car will fit just fine in your two-car garage, and you have space just in case you get another car. It’s probably good to have that little bit of extra space.
But you don’t ever expect to have 3 cars. You’re not that rich.
Now think about this: What if you still have your 1 car, but you built a 10-CAR GARAGE for it instead?

Suddenly there is A LOT of space wasted! You probably won’t ever own enough cars to fill the garage, and you essentially wasted valuable real estate (and money) in building the massive garage.
Good going.
This is how CHAR space in memory works. For every value, it will reserve the full amount of space according to the size you defined the column to be, regardless of how much is actually used.
This leads us nicely into our next regular character data type:
The VARCHAR data type
We use the VARCHAR data type when the size of the values we want to store will vary greatly.
VARCHAR is probably the most commonly used character data type
Let’s go back to our WarehouseEmployees table. We can see we set the FirstName, MiddleName, and LastName columns to be VARCHAR:
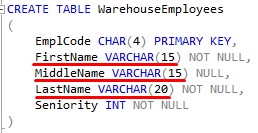
First, middle, and last names can be any number of characters long. Some names are very short, some names are very long. It wouldn’t make sense to use CHAR in that scenario.
The advantage VARCHAR has over CHAR is that VARCHAR will use only as much space as is needed.
Let’s look at some of the data in our LastName column for example:
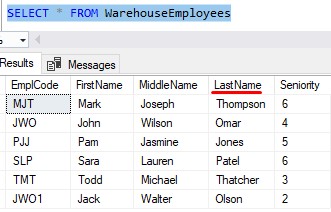
Take the last name “Omar” as an example. This name is only 4 characters long, meaning it needs 4 bytes of storage.
So how much space does SQL Server reserve for this value?
4 bytes.
If we had used CHAR instead, SQL Server would have reserved the full 20 bytes, which would be a huge waste.
Basically, when it comes to storing VARCHAR values, SQL Server says “I was prepared to give you 20 bytes of storage if you needed it, but I see you only need 4, so I’ll give you the 4 you need and give the remaining 16 back to the operating system“.
But if we had used CHAR instead, SQL Server would say “You said you needed 20 bytes, so you FREAKING GOT 20 BYTES. I don’t care how much space is wasted”
Yikes.
This is the advantage of VARCHAR. It stores the value using only as much space as the value needs. No wasted space!
The downside of VARCHAR
Let’s think about the downside of VARCHAR (spoiler alert: It’s not too bad)
If SQL Server uses 4 bytes to store “Omar“, think about what SQL Server would need to do if we needed to change the name “Omar” to something larger.
Maybe when we entered this data, we thought the employee’s last name was “Omar“, but it was actually “Omarlen“.
No problem, you would just issue a simple UPDATE statement:
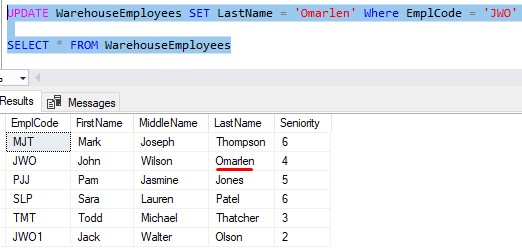
That’s easy enough, but think about what SQL Server had to do behind the scenes. SQL Server had to find and allocate 3 more bytes to fit the new value. If we were using CHAR instead, those 3 bytes would have already been there and ready to use.
It’s like buying another book when your bookshelf is already full. You’d have to go out and buy another bookshelf to fit everything. If you had a larger bookshelf from the start, you would’ve been ok.
Most people can live with this downside of VARCHAR, though. Technically yes, it’s more work when we need to reserve more space, but it’s really not that much work. The advantage of saved space is far greater than the disadvantage of occasionally needing to reserve more space.
2. The “Unicode” character data types
The use of Unicode character data types should be done deliberately.
Remember how I said regular character data types will use 1 byte per character?
Well, Unicode data types will use 2 bytes per character. But why?
Unicode data types are meant to be used if the data you are storing needs to be stored in multiple languages. Regular character data types, on the other hand, can store data in English and only one other language.
SQL Server needs that 1 extra byte per character in case you need to store the character in other languages.
So, like I said, Unicode data types should be used purposefully. If you know you are only going to store character data in English, it would be a huge waste of space to use Unicode data types.
Believe it or not, you already know the difference between NCHAR and NVARCHAR. They behave the same as their regular counterparts, with the only difference being how much space is used. Let’s talk about each.
The NCHAR data type
This Unicode data type, like it’s regular counterpart, will reserve the full size you have given it in memory for every value stored. But of course, it will use 2 bytes per character.
Imagine if I changed the EmplCode column to be NCHAR:
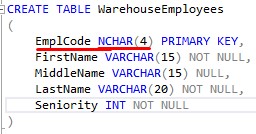
Let’s look at our WarehouseEmployees table one more time:
Take EmplCode “TMT” as an example. This value is 3 characters long, but it’s being stored with an NCHAR data type.
Pop Quiz: How much space is used for this value?
Answer: 8 bytes
Remember, CHAR and NCHAR don’t care how much space the value actually takes up. It’s going to reserve the full amount, regardless. And since we use NCHAR, it’s going to use double the amount of space.
The column is defined with a size of 4, which means SQL Server will reserve 8 bytes to store it’s values.
Seems like quite the waste if we’re going to store our initials in just English, don’t you think?
The NVARCHAR data type
Again, this is very similar to it’s regular counterpart. NVARCHAR will use only as much space as is needed, but again, it will still reserve 2 bytes for each character.
Imagine we used NVARCHAR for our FirstName, MiddleName, and LastName columns:
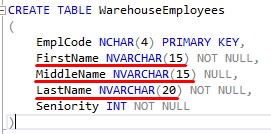
Here’s a look at our LastNames again:
So how much space is used to store the name “Jones”
Answer: 10 bytes.
The string “Jones” is 5 characters long. NVARCHAR will use just enough space to store those characters, and set aside 2 bytes for each since it’s Unicode. Therefore, the total space used by the value is 10 bytes.
I have to say it again: You need to be sure you want to use Unicode data types before using them. They take up much more space than their regular counterparts.
Next Steps:
Leave a comment if you found this tutorial helpful!
These 4 character data types are referenced in the following FREE Ebook:
FREE EBook on SQL Server Data Types!
In this guide, we discuss all these character data types and several other data types you should know as a database professional. Make sure you download it today!
Now that you understand character string data types, make sure you read up on character string functions!
Thank you for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
I hope you found this tutorial helpful. If you have any questions, leave a comment. Or better yet, send me an email!


