

The NVARCHAR data type is used to store character string data within our Microsoft SQL Server databases.
It’s important that you know how NVARCHAR works so that your database doesn’t waste space. In this very brief tutorial, we’ll discuss how NVARCHAR works and when you should consider using it.
NVARCHAR is listed in the following FREE guide:
FREE EBook on SQL Server Data Types!

This guide discusses the most common data types you will likely encounter as a database professional. You should definitely understand these common data types if you want to perform your job well. Download the guide today!
We’ll discuss these topics:
- What is NVARCHAR?
- What is a Unicode data type?
- An example of using NVARCHAR
- The downside of using NVARCHAR
- Tips about NVARCHAR
Let’s start from the top.
1. What is NVARCHAR?
NVARCHAR is a Unicode data type meant to store character string data. We use this data type when the size of the values we want to store will vary greatly.
We’ll learn how NVARCHAR is great for storing character string data in an efficient way.
The syntax for NVARCHAR is very simple. An example would be NVARCHAR(20). This will store a character string value with a maximum size of 20 characters.
We’ll look examples of using NVARCHAR in the next sections.
2. What is a Unicode data type?
NVARCHAR is a Unicode data type. But what is that?
It’s important to note that regular character data types (like regular VARCHAR) will use 1 byte of memory per character when storing a value.
Unicode data types will use 2 bytes per character. But why?
Unicode data types are meant to be used if the data you are storing needs to be stored in multiple languages. Regular character data types, on the other hand, can store data in English and only one other language.
SQL Server needs that 1 extra byte per character just in case you need to store the character in other languages.
This means that Unicode data types should be used deliberately. If you know you will need to store character data in several languages, go ahead and use NVARCHAR. Otherwise, if you know you are only going to store character data in English, it would be a huge waste of space to use Unicode data types.
3. An example of using NVARCHAR
Let’s take a look at the following table:
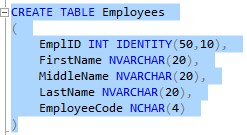
Notice our FirstName, MiddleName, and LastName columns all use the NVARCHAR(20) data type. This means each column can hold a string value that is at most 20 characters long.
Here’s the content of the table:
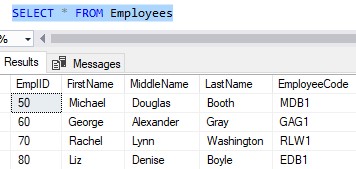
It’s easy enough to use the NVARCHAR data type when creating a table, but what is the advantage of using this data type?
The advantage of NVARCHAR
The NVARCHAR data type will use only as much memory as is required to store the value, and nothing more.
Let’s think about the FirstName of ‘George‘, which is only 6 characters long. Since Unicode data types use 2 bytes per character, this value is going to take up 12 bytes of memory.
Compare that to if the data type was NCHAR(20). NCHAR would reserve the entire amount of memory as defined by the data type. So to store the name ‘George‘, it would use 40 bytes of memory (2 bytes x 20 characters = 40 bytes of memory). It doesn’t matter that the name ‘George‘ only needs 12 bytes.
So essentially, out of the 40 bytes allocated, 12 are actually used and the remaining 28 are literally empty.
Does that sound like a huge waste of space? (say yes).
But again, NVARCHAR will use only as much space as is needed to store the value, and nothing more. There is no wasted, empty space!
4. The downside of using NVARCHAR
There are a couple of downsides to NVARCHAR. We’ve already discussed one downside, in that NVARCHAR will use 2 bytes per character as opposed to 1 byte for regular VARCHAR. If you think about it, this means any value stored using NVARCHAR will use twice as much space as it would if you used VARCHAR instead.
For example, storing the name ‘George‘ in VARCHAR would only use 6 bytes of memory. Remember earlier, we saw how storing ‘George’ in NVARCHAR would use 12 bytes, which is twice as much!
So if you don’t specifically need the extra capabilities of a Unicode data type (i.e. storing the data in multiple languages), it would be a huge waste of space to use NVARCHAR.
Another downside of NVARCHAR appears when we want to change a value. Think about the FirstName of ‘Liz‘, which is currently using 6 bytes of memory. What if we want to change this to the person’s full name of ‘Elizabeth‘? Well, SQL Server would need to find and allocated the required space needed to store this new, longer value, which appears to be 18 bytes worth.
If we used NCHAR(20) as the data type instead, we would already have that space available and allocated. SQL would not need to “find and allocate” anything. It would be no big deal to go from using 6 out of 40 bytes to using 18 out of 40 bytes.
However, understand that SQL Server is very fast at finding and allocating more space. It is a much worse sin to waste space, like what can happen if you use NCHAR inappropriately!
5. Tips about NVARCHAR
Here is a list of a few things you should know about NVARCHAR:
Tip # 1: You should use NVARCHAR when the values you want to store will vary greatly, and use NCHAR when the values will be similar in size.
NVARCHAR is the ideal choice when you want to store values of varying sizes because each value will use the minimum amount of memory needed to store the value, as we have learned. But what if you know all of your values are going to be the same size?
Take a look at the EmployeeCode column of our table. The value in this column represents the initials of the employee, plus a number.
For example, the employee Michael Douglas Booth has an EmployeeCode value of ‘MDB1‘.
(We use a simple number at the end in case two people have exactly the same initials. In that case, we can give the second person a different number from the first person to make them unique)
Most employees will likely have an EmployeeCode that is four characters long. That’s why the column is NCHAR(4). We don’t have to worry about wasting space because most people will use all four characters!
Tip # 2: The default size for NVARCHAR is 1
If you wanted, you could leave off the size specification and the size will default to 1. I suppose this is good to know if you want to make a column that stores a single character value, such as an ‘InStock‘ column that stores only ‘Y‘ or ‘N‘. Like this:
CREATE TABLE Products ( ProdID INT, ProdName NVARCHAR(20), InStock NVARCHAR --Stores only a single character )
Next Steps:
Leave a comment if you found this tutorial helpful!
If you found this tutorial helpful, don’t forget to download your FREE guide:
FREE EBook on SQL Server Data Types!
This guide discusses the most common data types you will likely encounter as a database professional. You should definitely understand these common data types if you want to perform your job well. Download the guide today!
Also, if you want to learn more about all the different character string data types, check out my full tutorial on the topic:
SQL Server character data types (and the differences between them)
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
I hope you found this tutorial helpful. If you have any questions, leave a comment. Or better yet, send me an email!


