

When you are first learning how to query SQL Server databases, you might find yourself thoroughly confused by the GROUP BY clause. I know I was, for sure.
You might ask yourself questions like:
“What columns am I allowed to use in the SELECT list?”
“Can I put more than one column in the GROUP BY clause?”
“HOW DOES THIS WORK?!”
Your life is about to get better. We’re going to discuss everything you need to know about using the GROUP BY clause.
The GROUP BY clause is part of the Top 6 tools you should know for writing AWESOME Select statements
If you want to learn more about other extremely common and useful query tools, check out that tutorial.
In this tutorial, we’ll discuss the following topics about the GROUP BY clause:
- What does the GROUP BY clause do?
- Examples of using the GROUP BY clause
- Tips and tricks
Don’t forget to Download your FREE 1-page Simple SQL Cheat Sheet on the GROUP BY clause!
Let’s get into it.
1. What does the GROUP BY clause do?
The GROUP BY clause allows you to collect and summarize data according to whatever groups you decide.
SQL Server has a term for when you “collect and summarize” data. They call it aggregating data. When you use the GROUP BY clause, you normally use it with an aggregate function (but you don’t always need to)
Some of the most common aggregate functions you will use with the GROUP BY clause are:
- COUNT() – Simply counts the number of rows per group you decide
- Examples: Counting the number of customers in each city
- SUM() – Adds together numeric data per group you decide
- Example: Adding how much money each customer has spent at our store.
- MIN() – Finds the minimum numeric amount per group you decide
- Example: Finding the smallest purchase made by each customer
- MAX() – Finds the maximum numeric amount per group you decide
- Example: Finding the largest purchase made by each customer
- AVG() – Calculates the average of the numerical values per group you decide
- Example: Calculate the average Sale Price per order
But again, the GROUP BY clause allows you to collect/summarize information according to whatever category you want.
I know, you’re still confused. I get it. The easiest way to understand the GROUP BY clause is to look at some examples!
2. Examples of using the GROUP BY clause
Ok, so like I said, we just need to work through some examples to fully understand the GROUP BY clause.
Let’s say you are a small business owner based out of Orlando, Florida, and you created a simple database to store information about your products, customers, and orders.
Your ‘Customers‘ table simply stores the first and last names of your customers, as well as the city they live in.
Here is the content of your ‘Customers‘ table right now:
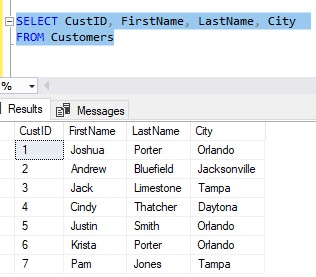
Pretty simple.
Let’s think about some groupings we can come up with based on this data.
It looks like we have shoppers in different cities. We have customers in our own city of Orlando, but we also have shoppers in neighboring towns, which is great!
But what if we wanted to know how many customers we have from each city?
In other words, we want to count the number of customers we have in each city (this is a hint).
Well, I suppose we could do this the hard way. I can manually look at the table and come up with the following breakdown:
Orlando – 3 customers
Tampa – 2 customers
Daytona – 1 customer
Jacksonville – 1 customer
That was easy enough with a total of 7 customers in our table. But what if I had 100 customers?
What if I had 231,877 customers? It would take us forever to figure out this breakdown.
But let’s think about how we are collecting/organizing customers in this breakdown. We are organizing them according to the city they live in.
In other words, we are grouping by city.
If we were to write a query to come up with this same breakdown, can you guess what we’ll need to put in our GROUP BY clause?
If you said city, you get a gold star.
Whenever you are thinking about the GROUP BY clause, you need to think about how you want to present the final result set. You need to say “I want the final result set to give me a breakdown according to ______“. The word you put in the blank will likely be the column you specify in your GROUP BY clause.
Ok, so let’s change our query to have a GROUP BY clause (but let’s not run the query yet):
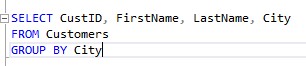
Nice.
And remember our hint earlier: We want to count the number of customers we have in each city.
So, any guesses for which aggregate we are going to use in our SELECT list?
If you guessed COUNT(), you get another gold star.
When it comes to COUNT(), there are actually two versions:
- COUNT(*)
- COUNT(<expression>)
- The <expression> would be something like a column name.
We’re going to focus on COUNT(*) for now. But just so you know, COUNT(<expression>) is used when you want to exclude NULL values when counting rows. Check out this tutorial for more details about the difference between the two COUNT aggregate functions:
The difference between COUNT(*) and COUNT(column): Answered!
Ok, so we want to count the number of rows we have for each city, which is exactly what COUNT(*) will do. Let’s put the COUNT(*) aggregate function in our SELECT list:

We’re almost to a fully functioning query!
The last thing to talk about is the column list. When I was learning about the GROUP BY clause, I had the hardest time figuring out what was allowed (or not allowed) in the column list. Maybe that’s your biggest question, too.
Let’s see what happens if we try to run our query as it is presently:
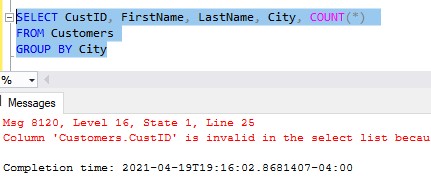
Here is that full error message:
Column ‘Customers.CustID’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
Ok folks, I’m going to give it to you in plain English: If a column isn’t also in your GROUP BY clause, or if it isn’t part of your aggregate function, it can’t go in the SELECT list.
So by including the CustID, FirstName and LastName columns in our SELECT list, we’re breaking that rule.
None of those columns are in the GROUP BY clause, and none of those columns are part of the aggregate function (in fact, no columns at all are part of the aggregate function).
That is the golden rule you need to remember.
If you think about it, it makes sense. Let’s take this fully functioning example of using the GROUP BY clause in a query:
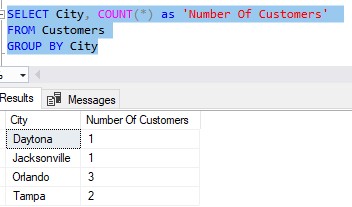
Cool, so this query gives us the information we wanted. But imagine if we also had the FirstName column in the final result set (which would be a violation, and would give us an error message). The imaginary result set would look sort of like this:
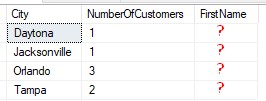
Folks, what do you expect to go here?
I suppose for the cities with only one customer, you might think it wouldn’t be a problem to see that customer’s first name.
But what about Orlando and Tampa?
There are three people in Orlando. Of those three, which of their FirstName’s do you think should go in the column? Or do you think maybe all three FirstName’s should squeeze into that single column, somehow?
Folks, that can’t happen.
With the GROUP BY clause, each group is represented by only one final result row. This means all columns appearing in the SELECT list must return only one result value per group.
For FirstName values, Orlando and Tampa would return 3 and 2 values, respectively. This would break the rule.
And no, the GROUP BY clause isn’t smart enough to predict the future, and know our groups Daytona and Jacksonville are going to return only one FirstName value. For example, even though you and I know there is only one customer in Daytona and one in Jacksonville, this query still fails:
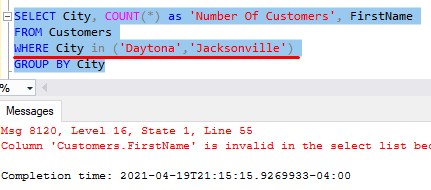
(That’s the same error message we got earlier)
3. Tips, tricks and links
Here is a list of tips and tricks to be aware of when using the GROUP BY clause.
Tip # 1: You can use more than one aggregate function in a query that uses the GROUP BY clause
Let’s take a look at this result set, which displays some information about all Orders in our system:
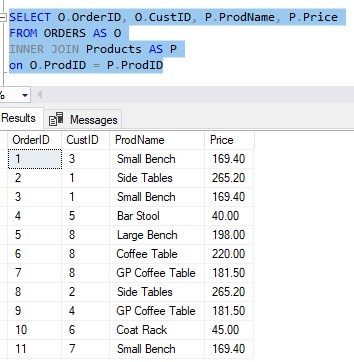
In every line of this result set, we can see the Order ID, the Customer ID of the person who made the order, what product the customer bought, and finally the price of that product.
What if we wanted to know how much money we have made from each product?
We would have a breakdown by Product, then a summation of all the Prices seen in this result set for each of those products.
Here’s the query, using the SUM() aggregate function:
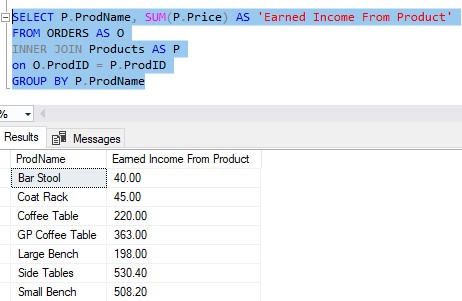
So what if we wanted to know how many of each Product was sold? We could add another aggregate function into our SELECT list:
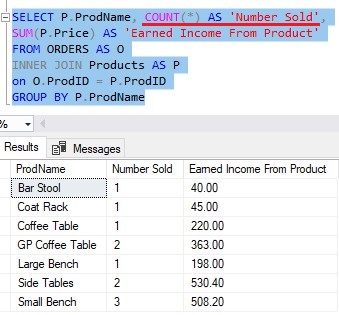
Now we know how many of each product has been sold, and the total income from each!
Tip # 2: You can have more than one column outlined in your GROUP BY clause
You’re certainly allowed to group on more than one criteria.
Take a look at this Employees table:
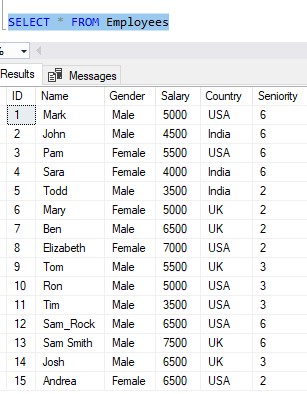
Notice we track each employee’s gender, salary, and the country they live in.
What if we wanted to know the average pay of men and woman from each country?
For example, we would like to see how much a woman in the United States makes compared to a woman in the United Kingdom. Through the use of the GROUP BY clause, we can find that out:
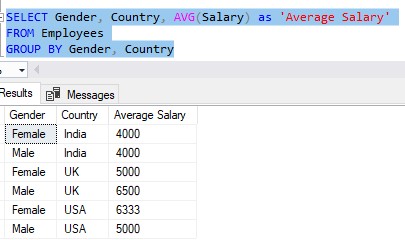
Of course, I still followed the rules: The columns outlined in our SELECT list are part of the GROUP BY clause or part of the aggregate function.
Tip # 3: You can filter the results of an aggregation using the HAVING clause
The HAVING clause serves as sort-of a WHERE clause to your GROUP BY clause. It’s used to apply a filter to the resulting values of your aggregate column.
For example, if we wanted to restrict the query above to show only Employees with an “Average Salary” greater than $6000, we can do that by using the HAVING clause:
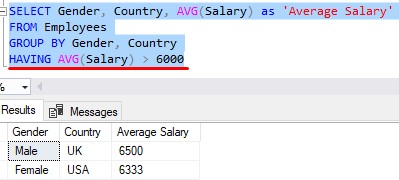
I have a full tutorial on the HAVING clause you should check out:
The HAVING Clause: How it works
Links
There is a great book called T-SQL Fundamentals written by Itzik Ben-Gan that goes over several core concepts you should know about SQL Server, including how to use the GROUP BY clause. You won’t regret owning this book, trust me. Definitely get it today!

Next Steps:
Leave a comment if you found this tutorial helpful!
If you found this tutorial helpful, make sure you download your FREE GUIDE:
FREE 1-page Simple SQL Cheat Sheet on the GROUP BY clause!
Be sure to check out my full tutorial on the HAVING clause. This clause is used in combination with the GROUP BY clause to filter the resulting values of an aggregated column. You should be familiar with how this clause works, too:
The HAVING Clause: How it works
Also, as mentioned earlier, the GROUP BY clause is part of the Top 6 tools you should know for writing AWESOME Select statements. If you want to learn more about other extremely common and useful query tools, check out that tutorial.
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, please leave a comment. Or better yet, send me an email!


Easy-to-follow tutorial! Felt very satisfied with solving the query in tip#2 before looking at the solution. Surprisingly, my query happened to exactly match yours, including the alias. Overall, a great tutorial, thanks Josh!
Because you helped me, I’ll like to help you. A couple of typos I noticed in this article are:
1. Introduction
“In this tutorial, we will the following topics about the GROUP BY clause:” is missing “discuss”.
2. Section 2
“If a column isn’t also in you GROUP BY clause, or if it isn’t part of your aggregate function, it can’t go in the SELECT list.” missing “r ” in you.
Glad you found the tutorial helpful! And thanks for outlining my typos. I’m sure this blog is RIDDLED with typos, unfortunately!