

Understanding how indexes work is a critical component to understanding how to write efficient queries in SQL Server. The first type of index you should know is the clustered index.
We will discuss the following topics about clustered indexes in this tutorial:
- What is a clustered index?
- How does a clustered index help our queries perform faster?
- How do we know we need a clustered index on a table?
- The syntax for creating a clustered index
- How do we change our queries so that they use the clustered index?
- What is the downside of using a clustered index?
- Altering, dropping, and other tips, tricks, and links.
Also, you’ll probably find the following FREE Ebook helpful:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Let’s get into it.
1. What is a clustered index?
A clustered index is a data structure that defines the physical storage order of data in a table. The data is ordered according to something called the clustered index key. The data is physically stored in this order on the hard disk.
The “data structure” I mentioned above has a name. It’s called the B-Tree. Retrieving data from a B-tree is very fast. It’s not too important to understand what a B-Tree is at the moment, but you’ll eventually want to go into more detail. Here is the full post about the B-Tree:
The B-Tree: How it works, and why you need to know
2. How does a clustered index help our queries perform faster?
There is a great analogy I always think of when it comes to understanding clustered indexes. The analogy is a DVD collection.
Take your own DVD collection as an example (or your book collection, or your magazine collection, whatever!). Are your DVD’s ordered alphabetically by title? Or maybe there is no order at all, and they are all sort-of thrown together?
Imagine how hard it would be to find a specific DVD if your collection looked like this:

Whenever you need to find a specific DVD, it might take you a minute to look through them all to find the one you want. This is, of course, because you need to look through the entire collection of DVD’s. Sure, you might get lucky and find the DVD you want sitting right on top. But you also might get unlucky, and the DVD you want is at the bottom of the heap!
What if your DVD’s were ordered alphabetically by Title instead?

It would take no time at all to find the DVD you want.
Finding data is easy if it’s ordered
Let’s say we want to find ‘Fight Club‘ in our DVD collection. If the DVD’s are ordered alphabetically, we can basically skip any DVD’s who’s title starts with the letters ‘A‘ through ‘E‘.
On that same idea, if we look through all the ‘F‘ DVD’s and don’t find ‘Fight Club’, we know we don’t need to look through DVD’s ‘G‘ through ‘Z‘ because we know it won’t be there.
(Maybe we forgot we let our friend borrow it and they haven’t returned it….you know who you are….)
Congratulations, now you understand the idea behind a clustered index.
And sure, I get it. If you only have, like, 10 DVD’s, it wouldn’t be hard to look through the unordered pile and find the one you want. But when it comes to SQL Server, you need to think BIG.
What if you had 100 DVD’s?
What if you had 953,765 DVD’s? It would take you hours to look through the heap of DVD’s you own.
(A table without a clustered index is called a heap. See what I did there?)
Allow me to seriously blow your mind for a minute. What if you looked through that collection of nearly 1 million DVD’s AND THE DVD YOU WANTED WASN’T EVEN THERE

Understanding the Clustered Index Key.
Let’s go back to the definition of a clustered index for a minute. I said:
“The data is ordered according to something called the clustered index key.”
In my analogy, the clustered index key would be the Title of your DVD’s. Going back to SQL for a minute, most tables have a primary key, and that primary key is usually an integer.
The most common practice is to use your primary key column as your clustered index key.
3. How do we know we need a clustered index on a table?
There are a few ways to see if your table needs a clustered index.
First, are queries to that table running slowly? This is sometimes an indication that the indexes on the table need to be tweaked (or an index needs to be created if one doesn’t exist at all).
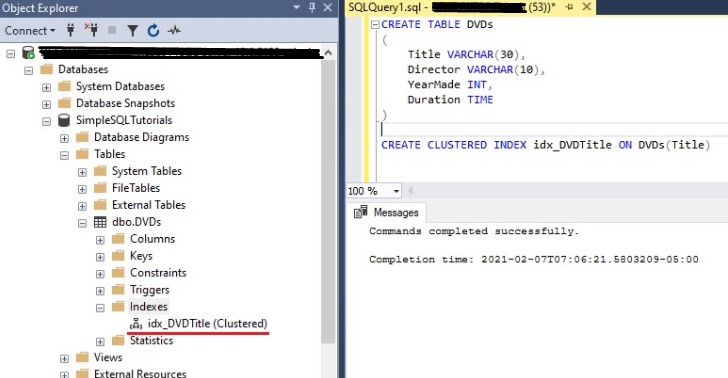
Second, if you want to see what indexes exist on your table, you can see that easily in the Object Explorer of SQL Server Management Studio. Within the Object Explorer, just expand the tree for your database, then find the table you want, then expand the Indexes tree, like so:
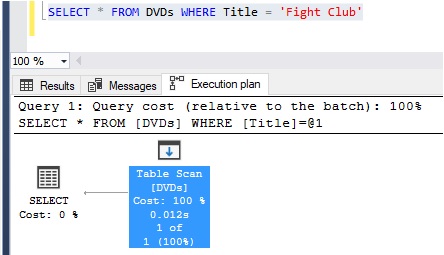
Another great way to see if your table could use a clustered index is to look at the execution plan for a query ran against that table. A simple query will do, like so:
SELECT * FROM DVDs WHERE Title = 'Fight Club'
If the execution plan shows a ‘Table Scan‘ object, the table does not have a clustered index, like so:
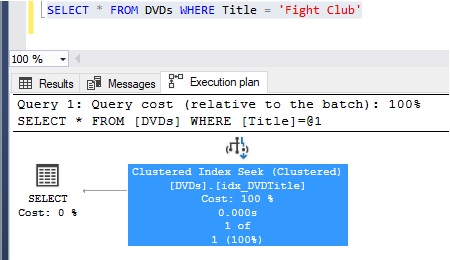
Conversely, if the query plan shows a ‘Clustered Index Seek‘ or a ‘Clustered Index Scan‘, you know the table has a clustered index, obviously.
4. The syntax for creating a clustered index
It’s simple:
CREATE CLUSTERED INDEX index_name ON table_name(column_name)
So as an example, say I have a DVDs table with a Title column that I want to set as the clustered index key. If I want to create a clustered index for this table and column, I would run the following statement:
CREATE CLUSTERED INDEX index_name ON DVDs(Title)
To reiterate, after this statement is ran, you would have a clustered index in your DVDs table, where the data is ordered physically on disk according to the clustered index key you specified, which is the Title column.
By the way, the index name can be anything you want. You could name the index “Spagetti” if you wanted.
5. How do we change our queries so that they use the clustered index?
You don’t need to do much to make a query use a clustered index. Normally, as long as the table has a clustered index, SQL Server will use that clustered index automatically when searching for rows to return from a statement (again, this is because the clustered index makes it so quick to look through the table, and SQL Server is always trying to return data in the quickest way).
Ideally, however, you’ll want to do your best to turn a ‘Clustered Index Scan‘ operator into a ‘Clustered Index Seek‘ operator in your Execution plan. With a Clustered Index Scan, SQL Server is still looking through the entire table to look for rows to potentially return. Of course, since the data is ordered in a meaningful way, this is a fast process, but we want to do our best to make it even faster!
The way you would make a query use the more ideal Clustered Index Seek operator would be to think about the filtering you are doing in your WHERE clause.
Maybe you don’t have a WHERE clause at all? Or maybe your WHERE clause is so general that SQL Server thinks it would be faster to just scan all rows instead of finding all the many rows that match your WHERE clause.
As a good rule of thumb, do your best to prevent SQL Server from needing to do Scans. Whenever you see a Scan, see if you can change it to be a Seek.
6. What is the downside of using a clustered index?
Going back to my DVD analogy for a minute, what would you need to do if you bought a new DVD, and you wanted to add it to your collection? Since our DVD’s are ordered by Title, your new DVD most likely wouldn’t go at the very end of your collection. Most likely, it would need to go somewhere in the middle. Think about what this means.
This means you will need to slide several DVD’s over in order to squeeze in the new one.
Again, think BIG, 1 million DVD’s big.
That is the downside of using a clustered index. If you need to add, remove or modify a clustered index key value, it might mean other data needs to be shifted, which can be expensive.
But thankfully, there is a solution.
As we learned earlier, we normally set the clustered index key to be the column being used as the primary key. A really good primary key data type is an integer. Integers don’t take much memory, and they are easy to increment. If our primary key column is an integer (making our clustered index key an integer), it would be really easy to add a new record to the end of the list.
Going back to the DVD analogy, say that over the years, whenever we bought a new DVD, we gave it a number.
For example, the first DVD we bought would be given number 1. The second DVD is given number 2. Third DVD, 3. So on and so fourth, all the way to DVD 953,765
If we kept our DVD’s in order by this number, instead of Title, it would be really easy to add DVD number 953,766 to the end of the list! No data shifting!
7. Altering, dropping, and other tips, tricks, and links.
Here are some important things to know about clustered indexes:
Tip # 1: You cannot change the definition of a clustered index via the ALTER statement
If you need to change the definition of a clustered index, you actually need to drop the index and re-create it.
To drop an index, use the DROP INDEX statement, like so:
DROP INDEX idx_Title ON Books
Notice you don’t need to specify the column name. Just the index name and the table it belongs to.
Note: This won’t work if your clustered index is on your primary key column (which it should be).
Notice how difficult it is to alter or drop a clustered index. Do your best to get this right the first time.
Tip # 2: You can only have one clustered index on a table
You can only have one clustered index on a table. Think about it. You can only order things one way.
You can’t order your DVD’s by Title, and also have them ordered by Director. It’s either one or the other.
Tip # 3: You can specify more than one column as your clustered index key
It’s definitely possible to use more than one column in your clustered index key.
Think about if you wanted to order your DVD’s by Director. You could certainly have more than one DVD directed by the same Director. In that case, maybe you want the DVD’s ordered by Director and then by Title:
CREATE CLUSTERED INDEX index_name ON DVDs(Director, Title)
Tip # 4: In Microsoft SQL Server, a clustered index in automatically created on columns you identify as being the primary key column.
You don’t need to worry about creating the clustered index in this scenario because it’s created for you. Here’s a rundown:
First I ran the CREATE TABLE statement on the right, then I found the new ‘DVDs’ table in the object explorer and found it’s indexes. We see index “PK_DVDs_461F42AD4E6213BB” was created automatically (not the best name, I know).
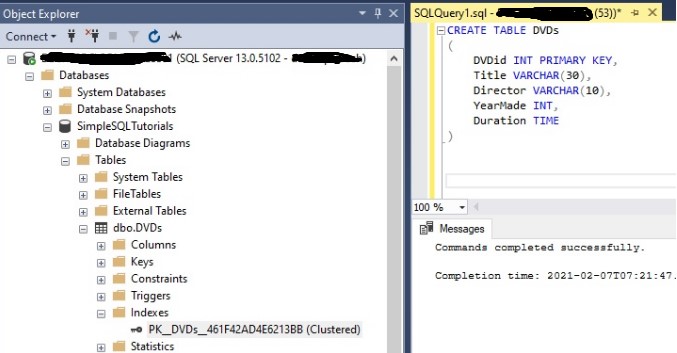
Tip # 5: You can create your clustered index in the definition of your CREATE TABLE statement
When we create the DVDs table, if we wanted to create a clustered index on the DVDid column (and give the index a meaningful name), we could do that directly next to the column definition:
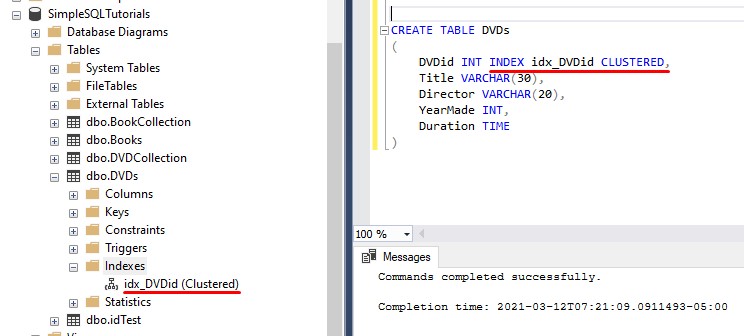
The trouble with that is we can’t include the word ‘PRIMARY‘ to make this column the primary key. If we wanted to outline the name of the clustered index, while also making the column the primary key, we would need to use the word ‘CONSTRAINT‘, like this:
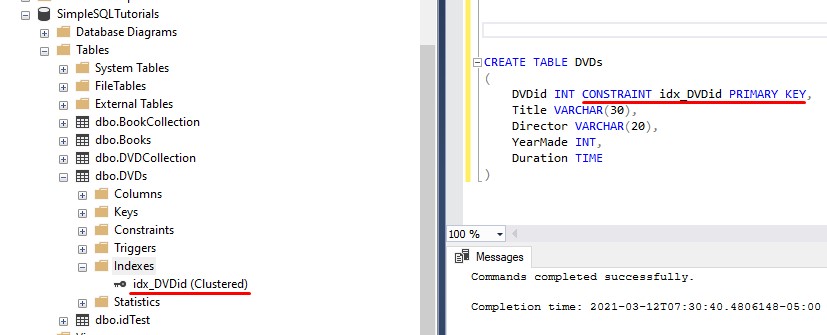
Tip # 6: It is important to make your clustered index key unique
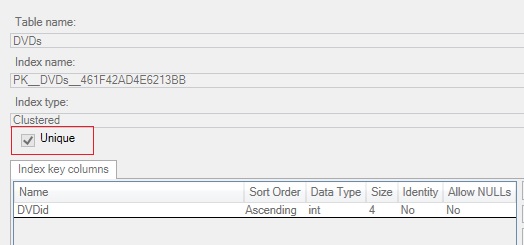
Again, this is done automatically for you when you create a primary key column. If we look at the definition of the index we created earlier, see that the Unique checkbox is enabled:
Links
There is an awesome book out there called Pro SQL Server Internals that discusses everything you need to know about indexes. The book helped me out tremendously when I was trying to understand indexes. It also discusses several other topics that are great to know about SQL Server. You won’t regret owning this book, trust me. Get it today!

Next steps:
Leave a comment if you found this tutorial helpful!
Also, make sure you download your FREE Ebook:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
At this point, you might be asking yourself, “Ok, but what is a nonclustered index?” Well, I put together another blog post that gives another great analogy that helps you understand nonclustered indexes.
Nonclustered indexes are also very important to understand. Proper use of nonclustered indexes will greatly improve the performance of queries ran against tables in your database.
You can check out that discussion here:
Nonclustered Indexes: The Ultimate Guide for the Complete Beginner.
As mentioned earlier, clustered indexes are made possible by a data structure known as the B-Tree. Take a look at my full tutorial on the B-Tree to understand what it is and how it works:
The B-Tree: How it works, and why you need to know
Thank you for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, leave a comment or even better, send me an email!


