In this tutorial, we will discuss one of the more common operators available to us when querying SQL Server databases: The UNION set operator.
We will also discuss it’s older sister: The UNION ALL set operator.
This tutorial will be the first of three on the topic of SQL Server Set Operators. The other two set operators are INTERSECT and EXCEPT. You should definitely be familiar with those set operators, too.
Set operators are part of the Top 6 tools you should know for writing AWESOME Select statements
If you want to learn more about other extremely common and useful query tools, check out that tutorial, too.
We will discuss the following topics about the UNION set operator:
- What is the UNION set operator?
- The syntax for the UNION set operator
- Rules you need to remember when using UNION
- What is the difference between UNION and UNION ALL?
- Tips, tricks, and links.
Don’t forget to Download your FREE 1-page Simple SQL Cheat Sheet on Set Operators!
Let’s start from the top:
1. What is the UNION set operator?
The UNION set operator will combine the results of two or more queries into a single result set.
That’s a very short definition, but it’s really all there is to it.
If you have two SELECT statements, for example, and you want the results of both displayed in a single result set (instead of two), you might be able to use the UNION set operator.
We’ll look at some examples in a bit.
2. The syntax for the UNION set operator
Well there’s not much to that either:
<SELECT statement 1> UNION <SELECT statement 2>
The syntax itself is fairly easy, as maybe you can tell. You just basically butt up two SELECT statement against each other and put the word UNION between them.
Kinda like a SQL Sandwich

While the syntax is easy, there are RULES you need to remember about the two (or more) SELECT statements.
Speaking of….
3. Rules you need to remember when using UNION
Let’s list them out:
- The two SELECT statements must have the same number of columns.
- The data types of each column in each SELECT statement must be compatible.
- In the final result set, the names of your columns are pulled from the names of the columns in your first SELECT statement.
- The only ORDER BY clause allowed in the query is a presentation ORDER BY clause after the last SELECT statement.
To further explain these rules, it would be best to look at a simple example.
We keep track of customer information using two tables: Customers and ContactInfo. The Customers table just has basic information about the customer, and the ContactInfo table holds information we have about how to contact them, such as phone number, email, and mailing address.
Here is the data from those two tables:
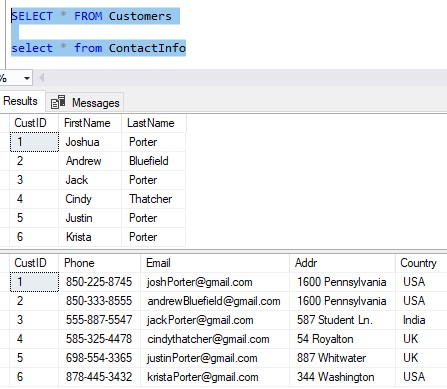
You can see the two tables are linked through the CustID. If we wanted to see a customer’s first name, last name, and country they live in, we could accomplish that through a very simple JOIN:
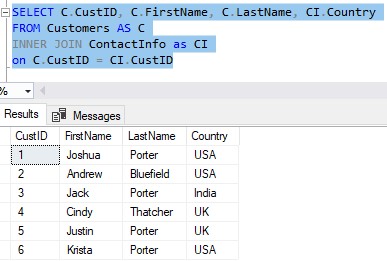
Need a rundown on what a JOIN is? I got you:
SQL Server INNER JOIN operator: The Ultimate Guide for Beginners
Cool. We also keep information about Employees who work for us:
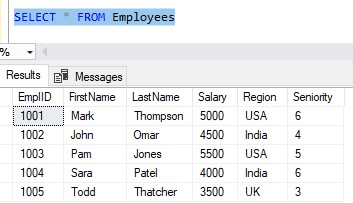
Now, let’s think about something we might want to see. What if we want to know what employees and customers live in the same country?
Ideally, our employees would deal with customers from their same region. It wouldn’t be ideal to have a salesperson from India working with a customer from the United States, for example. The language difference might be a problem, as well as the difference in time zones.
So we could just run both queries together, and see two separate result sets like this:
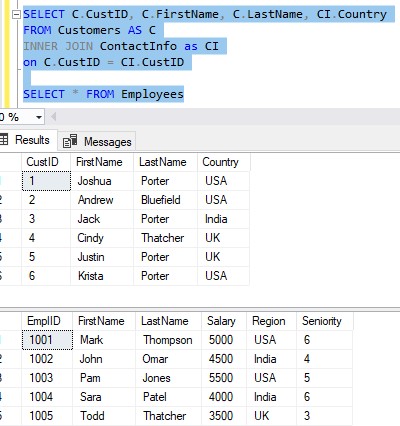
I guess this gets us what we want. For example, we can see Jack Porter is our only customer from India, so ideally our employee John Omar or Sara Patel would be the person working with Jack since they are all from India.
But what if we wanted to get this down to ONE result set? Remember, as a database developer, less queries are better than more.
This is where we could use UNION.
So remember, the UNION operator will make us a tasty SQL Sandwich. Just put the word ‘UNION‘ between the two SELECT statements (at first):
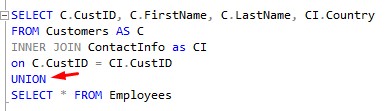
Notice we didn’t actually run this yet.
Remember what I said: The syntax is the easy part. The hard part is remembering the rules.
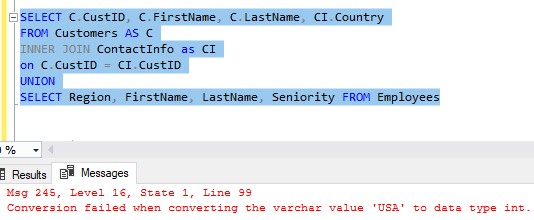
If we tried running all this right now, we would get an error message:
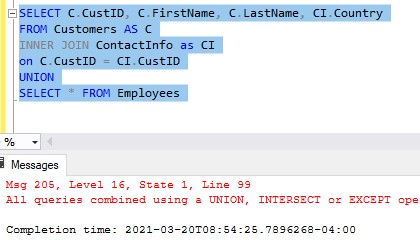
Here is that full error message:
All queries combined using a UNION, INTERSECT or EXCEPT operator must have an equal number of expressions in their target lists.
We are violating the first rule of SQL Club: You don’t talk about SQL Club, and the number of columns in your SELECT statements MUST BE THE SAME.
Remember these two queries we’re looking to combine:
The first SELECT statement returns 4 columns, the second returns 6 columns. Last time I checked, 4 does not equal 6
So, to resolve that problem in our UNION operator, we first need to get the column count the same. Maybe this will work?:
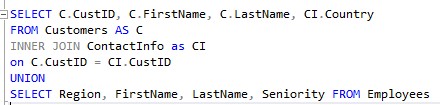
Both SELECT statements return 4 columns, so we’re good, right?
Nope
We get another error message:
The problem now is not as obvious.
The data types of each column in each SELECT statement must be compatible
Remember the second rule of the UNION operator: The data types of each column in each SELECT statement must be compatible.
SQL is going to walk down the column lists, one at a time, to see if the data types are compatible between the two SELECT statements. Let’s walk the list like SQL does.
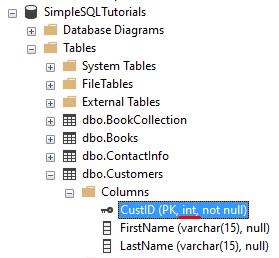
What’s the first column from each query? Well, it’s CustID from the first query and Region from the second query.
The CustID belongs to the Customers table, and it is an integer data type, as seen in the properties of the table:
The Region column belongs to the Employees table, and it is a varchar data type, which is a character string data type:
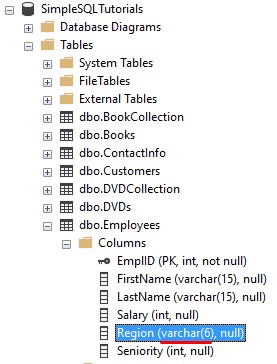
So the question is this: Is an integer compatible with a character string?
Well, try to solve this math problem:
324 + ‘Spagetti’ = ?
Um what? You can’t add the number 324 and the word ‘Spagetti‘ together. So, I’d say an integer is NOT compatible with a varchar.
Let’s think about the second and third columns from each query. They are the FirstName and LastName from the first query, and the FirstName and LastName from the second query (they are named identically in this case).
Looking at the column properties, it looks like these columns are, in fact, compatible.
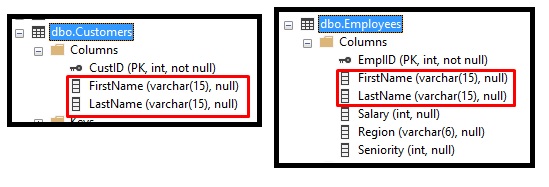
They are all varchar(15) data types. So the second and third columns are fine.
What about the last column from each query? That’s the Country column from the first query and the Seniority column from the second query.
Already, I sense this isn’t going to work.
Country is another character string (like ‘USA‘ or ‘UK‘), and Seniority is an integer (like 1, 3, 5, etc.). We already tried adding a character string to an integer and saw it doesn’t make sense. So, I’d say these columns are also not compatible.
Let’s see how we can fix our query. Let’s first look at the Country and Region:
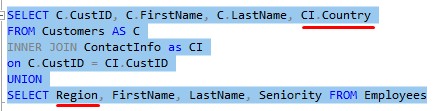
We need to get these two columns together. Let’s move the Region column to the end (and move ‘Seniority‘ to the front):
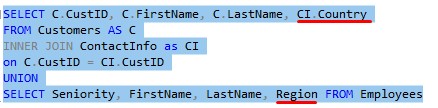
Perfect! Now the country information will be in the last column of our final result set.
Hmm, but let’s talk about the first columns: CustID and Seniority.
These columns are both integers, so they are compatible. So we’re not breaking any rules…..
But does that make any sense? Remember, the value from each of these columns will be in the same single column in the final result set. You’re saying you want to see the ID of your customers and the seniority level of your employees all in the same column?
Wouldn’t it make much more sense to see the ID of your customers and the ID of your employees in the same column?
Yes, it would. So let’s change the second query:
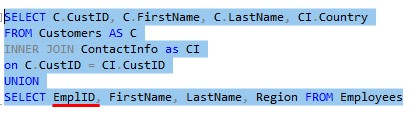
This makes much more sense. We’re showing ID information for our customers and employees all in the same column. I guess the point I want to make is that you can have your syntax correct, and be following all the rules, but the data you return might still be wrong in one sense or another.
So let’s look at the query now:
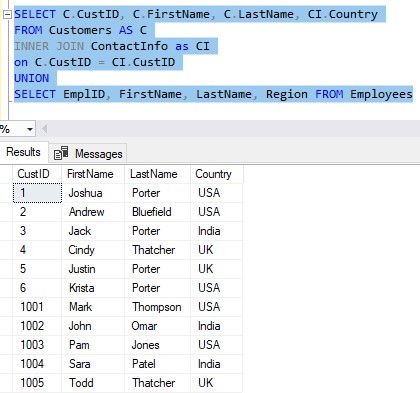
While we’re on the topic of “things not really making sense“, let’s think about something else. I want to point out another strange thing you might notice in the CustID column of the result set.
The values in this column aren’t all customer ID’s, are they? No, there are some employee ID’s mixed in there, too.
So, instead of the first column being called CustID, maybe it would make more sense to just call it PersonID, like so:
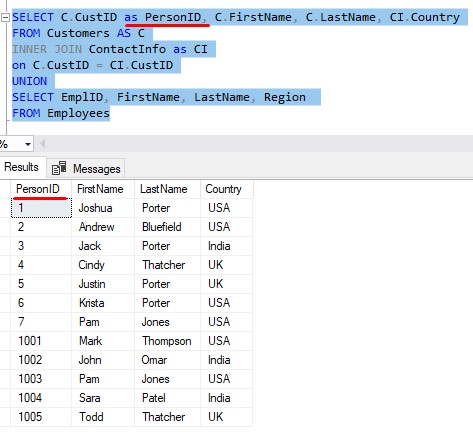
Awesome.
You’ll notice we only needed to use the alias ‘PersonID‘ in this first query. We can do this because of our next rule about the UNION set operator: In the final result set, the names of your columns is pulled from the names of the columns in your first SELECT statement.
Cool.
But wait, there’s another problem. We sort of don’t know which rows are customers, and which are employees.
Sure, with only 11 rows in the result set, it wouldn’t be too hard to reconcile which people are employees and which are customers. But remember, with SQL Server, you need to THINK BIG. What if we had 1 million customers, and 200 employees?
So, how are we going to distinguish Customer rows from Employee rows?
Well, a neat trick is to hard-code a column to each of your queries, and use that column as an identifier.
Check this out:
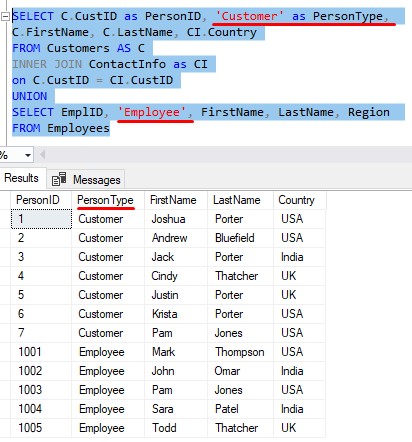
In our first query, we say the second column is simply the word ‘Customer‘. For all rows returned from the first query, the word ‘Customer‘ will be seen as the second column value.
Same idea if true for the second query. The second column is hard-coded to the word ‘Employee‘. For all rows returned from the second query, the word ‘Employee‘ will be seen as the second column value.
And remember, we only need to specify the column alias ‘PersonType‘ in the first query.
Now, let’s think about the next and final rule about the UNION operator: The only ORDER BY clause allowed in the query is a presentation ORDER BY clause after the last SELECT statement.
This does NOT work:
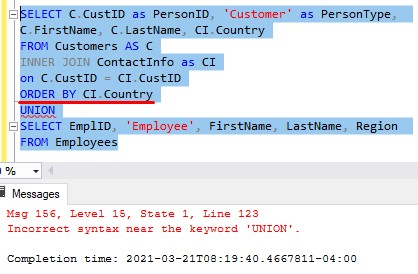
Ok, let’s remove that ORDER BY clause, and put one after the last SELECT statement:
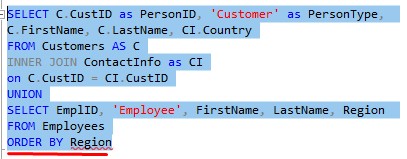
Is this going to work?
Well, the red squiggly line under the word Region is a clue there is a problem.
We need to think back to our other rule about the UNION set operator: In the final result set, the name of your columns is pulled from the name of the columns in your first SELECT statement.
This also means the column we choose to order by must be one of the columns in that first SELECT statement.
If we wanted to order the results by country, we need to say ORDER BY CI.Country, like so:
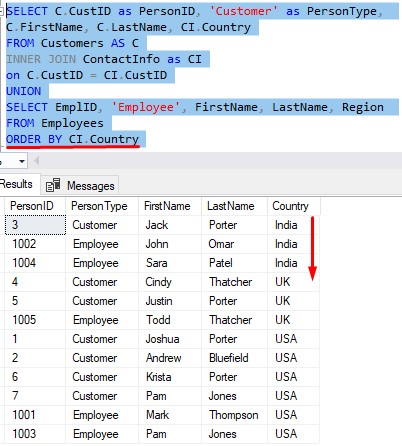
And remember, this ORDER BY clause can only be after the last query.
4. What is the difference between UNION and UNION ALL?
It’s pretty simple: UNION will remove duplicate rows from the final result set, while UNION ALL will not remove duplicate rows.
Let’s say you are a small business owner, and you have two stores. One is in Denver Colorado and another in the neighboring town of Boulder Colorado. You collect customer information for customers at each location, as seen here:
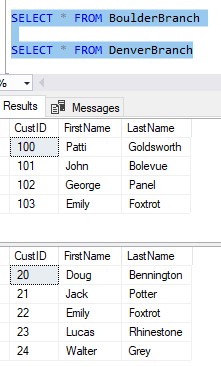
Notice there is a customer who exists in both the BoulderBranch table and the DenverBranch table.
It’s Emily Foxtrot.
Emily lives in Boulder, but works in Denver, so she actually shops at both locations. Both locations have collected her first and last name.
What if we wanted to see the first and last names for all customers we have in our database, for both locations? Well, we can do that with a very simple UNION:
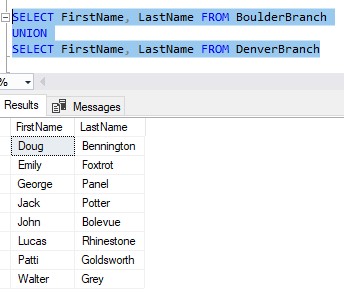
Notice Emily is seen only once.
Now, maybe we do want to see her twice. In that case, we should use UNION ALL:
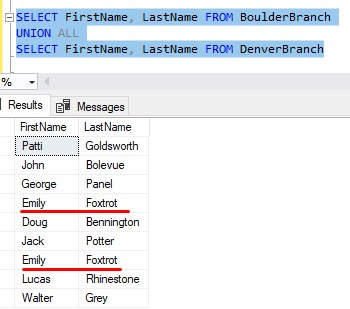
So we’re seeing her twice: Once from the BoulderBranch table, then again from the DenverBranch table.
In situations where you want to keep duplicates, you should use UNION ALL.
I actually have a full tutorial dedicated to the topic of UNION vs UNION ALL. Check it out:
UNION and UNION ALL: What’s the difference?
5. Tips, tricks, and links.
Here is a list of some helpful tips and tricks you should know about the UNION set operator:
Tip # 1: If you know your result set won’t contain duplicate rows, you should choose to use UNION ALL instead of UNION
The UNION operator actively tries to look for and remove duplicate rows. If you are confident your result set simply won’t have duplicate rows, SQL Server would be wasting time and energy trying to find said duplicate rows.
So in our larger example, since we know there won’t be duplicates (especially because of that ‘PersonType‘ column), we probably should have used UNION ALL:
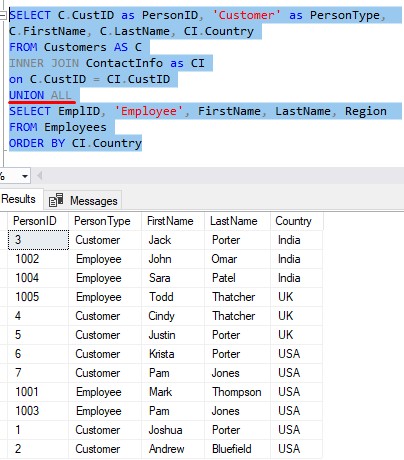
Tip # 2: You can certainly have more than one UNION or UNION ALL in a query
In all our examples so far, we have been doing a union between two queries. However, you can perform a union between several queries if you needed to. As you might guess, you would just outline the word UNION (or UNION ALL) again, followed by the next query you want to include.
For example, say you open a third store location:
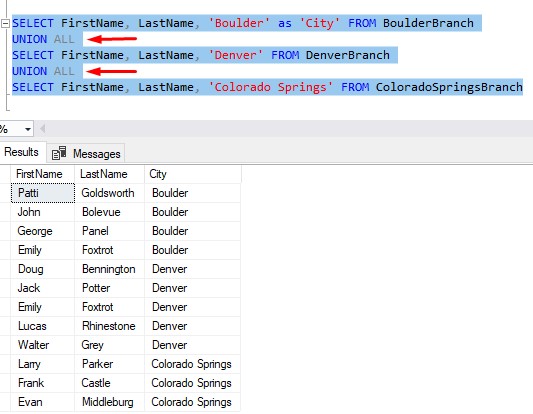
Easy, right?
Tip # 3: Remember, only the names of columns in your first query are returned in the final result set.
If you created a column alias in your second query, for example, you wasted your time! That alias won’t be seen!
Links
There is a great book called T-SQL Fundamentals written by Itzik Ben-Gan that goes over several core concepts you should know about SQL Server, including how to use the UNION set operator. The book actually has an entire chapter dedicated to the discussion of all the different set operators. You won’t regret owning this book, trust me. Definitely get it today!

Next steps:
Leave a comment if you found this tutorial helpful!
If you found this tutorial helpful, don’t forget to…
Download your FREE 1-page Simple SQL Cheat Sheet on Set Operators!
Be sure to take a look at the tutorials for the beloved cousins of the UNION operator: INTERSECT and EXCEPT. These two set operators are also very common, so it is important you know how they work and how to write them. Here’s the links:
The INTERSECT Set Operator: Everything you need to know
The EXCEPT Set Operator: Everything You Need to Know
You also need to know that certain set operators take precedence over others. This is in situations where you need to write a query involving more than one set operator. Make sure you understand set operator precedence by reading this article:
Set Operator Precedence: Explained
Finally, set operators are part of the Top 6 tools you should know for writing AWESOME Select statements. If you want to learn more about other extremely common and useful query tools, check out that tutorial.
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, leave a comment! Or better yet, send me an email!