

If you know a thing or two about Clustered indexes and Nonclustered indexes, you might be looking to “round out” the topic with an understanding of what a Unique index is.
Unique indexes are a great way to enforce uniqueness in a column other than the Primary Key column.
If we remember, the Primary Key column will guarantee every value in the column will be unique. But what if we want a different column to also be 100% unique? We can’t add a second Primary Key column because a table can only have one Primary Key.
So, our best solution is to use a Unique Index!
In this tutorial, we will discuss everything you need to know about a SQL Server Unique Index. We will discuss the following topics:
- What is a Unique Index?
- Syntax for a Unique Index
- Examples of a Unique Index on a column
- What’s the difference between a Unique Index and a Unique Constraint?
- Tips and tricks
Also, you’ll probably find the following FREE Ebook helpful:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
I also have a FREE Ebook that gives you a quick summary of all the constraints in SQL Server, including:
- PRIMARY KEY
- FOREIGN KEY
- UNIQUE
- DEFAULT
- CHECK
Download it here:
FREE Ebook on SQL Server Constraints!
Let’s take it from the top:
1. What is a Unique Index?
A Unique Index is placed on a column to guarantee there will be no duplicate values within that column. Each value in that column is guaranteed to be unique.
As I said earlier, this type of index is a great way to enforce uniqueness on a non Primary Key column.
Think about when you might want column values to be unique. Maybe you need to store your Employees’ social security numbers, or the VIN numbers for all the vehicles in your inventory. These values all need to be unique, but maybe you specifically don’t want to use these values as the Primary Key for your table because they are sort-of large.
Instead, you can set up a Unique Index to apply the same unique-ness requirement to a different column. It’s a very handy thing to know.
2. Syntax for a Unique Index
The syntax is very straightforward:
CREATE UNIQUE INDEX index_name ON table_name(column1, column2...)
The index_name can be anything you want, but you should always use a name that makes sense.
The table_name is of course the table you want to add the Unique Index to.
Finally, the list of columns in parentheses are the columns you want to set the Unique Index key on. It can be just a single column, or you can have multiple. We’ll look at examples in the next section.
3. Examples of a Unique Index on a column
Let’s actually create some data to show how useful this kind of index can be. We’ll create an EmployeeDetail table first:
CREATE TABLE EmployeeDetails ( EmplID INT PRIMARY KEY IDENTITY, FirstName VARCHAR(20), MiddleName VARCHAR(20), LastName VARCHAR(20), SSN VARCHAR(12) )
Notice we put a PRIMARY KEY constraint on the EmplID column. It also has the handy IDENTITY property.
Cool, now let’s populate it with a few rows:
INSERT INTO EmployeeDetails (FirstName, MiddleName, LastName, SSN)
VALUES
('Doug','Alexander','Bennett','333-22-9999'),
('Susan','Josephine','Rice','888-44-0000'),
('Gary','Valhalla','Smith','222-99-2222')
That was easy. Let’s look at the data in our table:
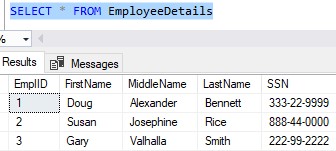
The Social Security Number example
This first example is a classic example you will see floating around the internet. It would be a problem if more than one person had the same social security number, right? Each person is supposed to have their own unique number, so it only seems fitting to enforce that kind of rule on our data.
Let’s try adding a new person with the same SSN as another person in our table:
INSERT INTO EmployeeDetails (FirstName, MiddleName, LastName, SSN)
VALUES
('Michael','Jones','Walker','222-99-2222')
Notice this new Employee has the same SSN as an existing Employee, Gary Valhalla Smith. Since we don’t have a constraint in place yet, the row get’s inserted just fine:
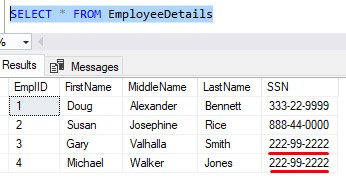
Folks, this ain’t good.
What we should have done was create a Unique Index on the SSN column, so that it’s not possible to add another Employee with the same SSN as a current Employee.
Let’s go ahead and create that unique index. But first, we need to clean up this data.
If data already exists, values need to be unique before you can add a Unique Index
Let’s try to run our CREATE UNIQUE INDEX statement right now:
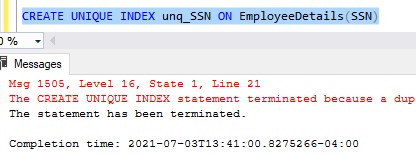
Here’s that full error message:
The CREATE UNIQUE INDEX statement terminated because a duplicate key was found for the object name ‘dbo.EmployeeDetails’ and the index name ‘unq_SSN’. The duplicate key value is (222-99-2222)
We are getting this error message because there is already duplicate data in the column. If you are trying to add a Unique Index to an already-populated column, the first thing you should do is eliminate duplicate data.
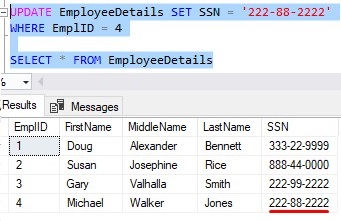
So, let’s fix the data and change the SSN of our newest Employee. A quick UPDATE statement will do:
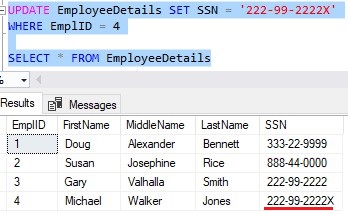
Cool. Now we should be able to run our statement just fine:
CREATE UNIQUE INDEX unq_SSN ON EmployeeDetails(SSN)
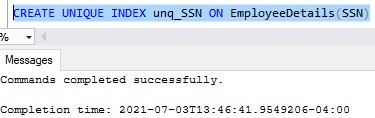
Awesome. Now if we try to UPDATE our new employee to have the same SSN as an existing Employee, we get an appropriate error message:
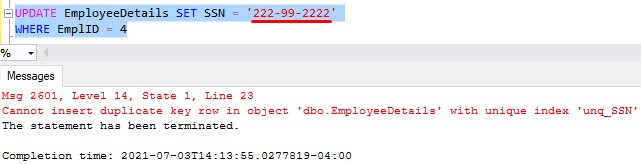
Here’s that full message:
Cannot insert duplicate key row in object ‘dbo.EmployeeDetails’ with unique index ‘unq_SSN’. The duplicate key value is (222-99-2222)
We get the same error message if we also try to INSERT a duplicate SSN:
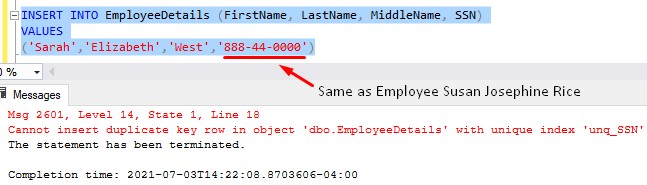
Just to show you the cleaned up data, here is a quick UPDATE to change the SSN of our newest employee, so that all rows contain a unique SSN number:
4. What’s the difference between a Unique Index and a Unique Constraint?
Folks, there really isn’t any.
They are both used to achieve the same goal, which is to guarantee column data is unique. The two solutions even perform the same. You don’t see a performance advantage of one over the other.
If you create a Unique Constraint, it will still create an index to maintain the constraint. The reason one might choose to create a Constraint over an Index is to basically make the purpose of the index clear.
My friend Pinal Dave over at SQLAuthority.com has a very short, to-the-point tutorial on the “difference” between the two. Check it out: SQL SERVER – Difference Between Unique Index vs Unique Constraint
5. Tips, tricks, and links
Here is a list of tips and tricks you should know about the Unique Index:
Tip # 1. How to drop the index
It’s simple, just use the DROP INDEXcommand:
DROP INDEX index_name ON table_name
For example, here is how we would drop our index:
Tip # 2. You can have more than one column in the index
As I mentioned earlier, you can definitely have more than one column as part of your Unique Index. For example, if we wanted to ensure we could never have two or more Employees with the same First, Middle, and Last name, we could set up another Unique Index:
CREATE UNIQUE INDEX unq_Names ON EmployeeDetails(FirstName, MiddleName, LastName)
Now, there can never be two or more rows that have the same combination of First Name, Middle Name and Last Name. This would be another great constraint to have. It would be strange if two people had exactly the same name. If someone were trying to insert the exact same name as another person, I would guess that user is actually making a mistake and is unknowingly trying to enter a duplicate employee. The constraint will stop that from happening!
Tip # 3. You can have more than one Unique Index on a table
We now have two Unique Indexes on our EmployeeDetails table, which is absolutely fine. Think about how this is different from a Primary Key column, though. We can only have one column set as the Primary Key.
This is the nice thing about Unique Indexes. You can have more than one on a table!
Tip # 4. There can be one NULL value in your column
This is different from the Primary Key column, where you can’t have any NULL values at all. You’re allowed to have one (and only one) NULL value in your unique column. If we think about it, NULL is just another possible value in the column, right?
Check out this tutorial if you want to understand a thing or two about NULL: SQL Server NULL: Are you making these 7 mistakes?
Tip # 5. The Unique index is created as nonclustered by default
In our CREATE UNIQUE INDEX statement, you can include the word ‘NONCLUSTERED‘ if you want to (like this: CREATE UNIQUE NONCLUSTERED INDEX), but understand the unique index will be created this way by default. So the word ‘NONCLUSTERED‘ is optional.
You can make it clustered if there isn’t already a clustered index on the table in question (because there can only be one clustered index on a table).
Take a look at my Clustered Index and Nonclustered Index tutorials if you’re not really sure what the difference is.
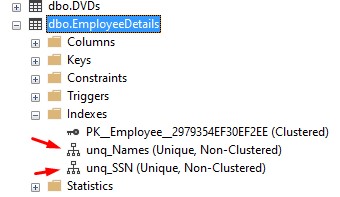
Tip # 6. How to locate your Unique Index in the Object Explorer
It’s easy. Just expand the table in question, and there will be an Indexes folder:
Next Steps:
Leave a comment if you found this tutorial helpful!
Also, make sure you download your FREE Ebook:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
Or if you prefer, I have another FREE Ebook that gives a quick summary of all the constraints available to us in SQL server. Download that guide here:
FREE Ebook on SQL Server Constraints!
If you need a quick rundown on what a Clustered Index is, take a look at my full tutorial for beginners:
SQL Server Clustered Index: The Ultimate Guide for the Complete Beginner
While you’re at it, you should learn what a Nonclustered Index is, too. Unique Indexes are created as nonclustered by default, as you know. Check it out:
Nonclustered Index in SQL Server: A Beginner’s Guide
Don’t forget about Included Columns. Those are used very widely in Nonclustered Indexes to speed up performance.
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, please leave a comment. Or better yet, send me an email!


