
In this discussion, we’ll talk about the younger brother of the clustered index: The nonclustered index.
In a separate discussion, we talked about how understanding and using clustered indexes is very helpful towards writing efficient queries in SQL Server. If you missed that discussion, you can find it here:
Clustered Indexes: The Ultimate Guide for the Complete Beginner
In this discussion about nonclustered indexes, we’ll answer the following questions:
- What is a nonclustered index?
- How does a nonclustered index help our queries?
- How do we know we need a nonclustered index on a table?
- What is the syntax for creating a nonclustered index?
- How do we change our queries so that they use the nonclustered index?
- The downside of nonclustered indexes
- Altering, dropping, and other tips, tricks, and links.
Also, you’ll probably find the following FREE Ebook helpful:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
And so it begins:
1. What is a nonclustered index?
A nonclustered index is a data structure that defines the order of rows according to a column you specify, known as the nonclustered index key. It stores these rows in memory, and will store a pointer to the row that exists in the clustered index (if the table has a clustered index). If the table doesn’t have a clustered index, the nonclustered index will store a pointer to the physical address of the row on disk instead (not ideal).
I know this doesn’t make much sense at the moment, and that’s ok. The best way to understand a nonclustered index is to think of an analogy, as outlined in point # 2.
2. How does a nonclustered index help our queries?
To understand nonclustered indexes, lets think of a great analogy: A book collection.
Let’s examine this picture of my book collection:
![]()

Before you start guessing, the numbers do not represent the nonclustered index. They represent the clustered index. The books are simply in order by the clustered index key, which is just an integer. Notice they are NOT in order by Title.
This is the nonclustered index:

Let’s examine what we did here. We created a nonclustered index called idx_Title, where the nonclustered index key is the Title. Of course, this means entries in the nonclustered index will be stored in alphabetical order by Title.
Remember what I said earlier: A nonclustered index will store a pointer to the row that exists in the clustered index if the table has a clustered index.
That’s why you see ‘pointer(X)‘ next to each entry in the nonclustered index. The number ‘X‘ represents the clustered index key value.
So let’s think about how this nonclustered index helps us. Say we want to find a book in our collection. Are we going to know the BookID off hand? Probably not. But are we going to know the Title of the book we want?
Probably so.
If we know the Title of the book we want, we can look through our nonclustered index pretty easily, since it is ordered alphabetically in that way.
So if we want to find “T-SQL Querying“, we can look through our nonclustered index, skipping any books whose title starts with letters ‘A’ through ‘S’.
Also, on that same idea, if we look through the ‘T’ books and don’t find the one we want, we know we don’t need to look through books ‘U’ through ‘Z’ because we know it won’t be there!
But in this case, the book we want is referenced in the nonclustered index, which is excellent. If we then want to find that book in our clustered index, we just look at the pointer. In this case, it is 6. Using the clustered index, we can easily find book 6 in our collection!
And sure, I get it. This seems like a waste of time for a total of 17 books. But what if you had 100 books?
What if you have 202,982 books?
If you didn’t have the nonclustered index, and you wanted to find a book by it’s Title, you would basically need to scan through the entire collection, starting from the beginning, to find the book you want.
And WHAT IF THE BOOK YOU WANTED WASN’T EVEN IN YOUR COLLECTION?

Congratulations, now you understand the idea of a nonclustered index.
A nonclustered index provides a fast way to find a row when filtering on a column that is NOT the clustered index key column.
3. How do we know we need a nonclustered index on a table?
There are a few ways to know if your table can benefit from a clustered index
First, are your queries performing slowly? This is usually a good indication that the indexes need to be tweaked (or maybe the table doesn’t have any indexes at all).
Another way is to take a look at the execution plan for a simple query to that table. For example, you could run the following query:
SELECT Title FROM Books WHERE Title = 'How to win friends and influence people'
Right now, the Books table does not have a nonclustered index on the Title column (but it does have a clustered index on the BookID column).
Knowing that, the execution plan looks like this:
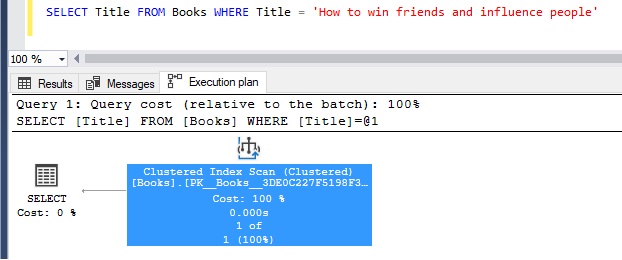
Again, since we are filtering our query on a column that is not the clustered index key, SQL will need to scan through the entire table to find the row we want.
Yes, since the table has a clustered index, this process is faster than it would be if the table were a heap. But it’s still not as fast as it could be.
(By the way, in case you don’t know, a table without a clustered index is referred to as a heap)
Now, if we add a nonclustered index to the Books table, Title column, the execution plan changes to this:
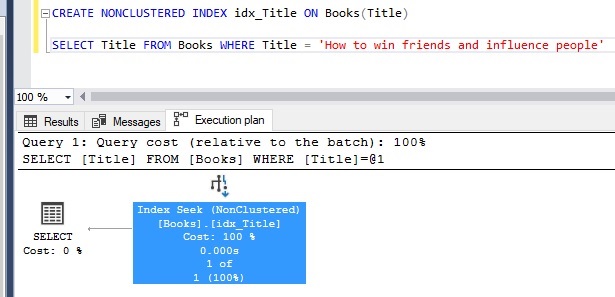
If you remember from my previous post about clustered indexes, we’re always trying to get our queries to display a ‘Seek’ operation, instead of a ‘Scan’ operation.
4. What is the syntax for creating a nonclustered index?
It’s simple:
CREATE NONCLUSTERED INDEX index_name ON table_name(column_name)
In fact, SQL assumes when you use the word ‘INDEX‘ that you are talking about a nonclustered index. So you could omit the word ‘NONCLUSTERED‘ if you wanted:
CREATE INDEX index_name ON table)name(column_name)
Here is an example in SQL Server Management Studio:
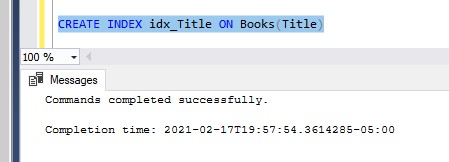
Also, if you wanted to create the nonclustered index as part of the table definition when you create the table, you can do it there. Here is an example of creating the Books table that creates a nonclustered index on the Title column:
CREATE TABLE Books ( BookID INT PRIMARY KEY, Title VARCHAR(40) INDEX idx_Title NONCLUSTERED, Author VARCHAR(15), Pages INT )
And again, you could leave out the work ‘NONCLUSTERED‘ and SQL will know you want the index to be nonclustered.
5. How do we change our queries so that they use the nonclustered index?
The best way to get your queries to use your nonclustered index is to look at the WHERE clause of your queries against that table, and also what columns you are returning in your SELECT list.
You’ll want to make sure the column in your WHERE clause is the column you specified to be your nonclustered index key column.
And remember what I said earlier: We don’t like seeing ‘Scans’ in the execution plan for a query. If you see a scan, you should do your best to get it to change to a ‘Seek’ by narrowing down your query results.
6. The downside of nonclustered indexes
You might be thinking to yourself, “Well heck, why don’t I just make nonclustered indexes for all my columns? That way, if I need to retrieve data from any column, it will be fast!”
Unlike a clustered index, there is potentially a major downside to using nonclustered indexes.
Let’s think about something. When we wrote down the Title for all our books on that piece of paper, we were basically duplicating data. The title of a book is not only on the book itself (obviously), but it is also on my piece of paper.
This can be bad for a couple reasons. First, it simply takes up more space on my desk. Now I have yet another piece of paper filling my desk, which has a finite size.

The memory available on a server is finite, so when we duplicate data, we take up space that could be used for something else.
Second, what if we need to change the title of one of our books? (in real life, I understand you can’t just change the title of a book, but in SQL, you absolutely can).
If we change the Title of a book, SQL will need to change it in two places:
- The main place on disk where the Title lives (of course)
- The nonclustered index.
Going back to our analogy, if we changed the Title of a book on our shelf (again, we’re in pretend land), we would also need to update it on our piece of paper!
(Let me make something clear. In SQL Server, if you need to update a Title, you only need to issue ONE update statement. I’m just saying behind the scenes, SQL will need to change it in TWO places. I don’t want you thinking you need to perform two updates in two different places!)
The same idea is true for not only updating data, but also adding or deleting data. If you add a new book, SQL will need to add a copy of the Title to the nonclustered index, which takes time (and also uses memory).
If you delete a book, SQL will need to make sure it gets removed from the nonclustered index as well, which again takes time.
7. Altering, dropping, and other tips, tricks, and links.
Here are some helpful things to know about nonclustered indexes:
Tip # 1: You can’t change the definition of a nonclustered index via the ALTER statement
If you need to change the definition of a nonclustered index, you actually need to drop the index and re-create it.
To drop an index, use the DROP INDEX statement, like so:
DROP INDEX idx_Title ON Books
Tip # 2: It’s good to “Include” other columns in your nonclustered index
As we have discussed, SQL Server can use a nonclustered index to retrieve information faster. But when looking through a nonclustered index, what if the columns in the SELECT list ask for column data that is not part of the nonclustered index?
For example, think about this query:
SELECT Author FROM Books WHERE Title = 'How to win friends and influence people'
Sure the WHERE clause specifies the column used in my nonclustered index, but the query doesn’t ask for only the Title, does it. It also asks for the ‘Author‘ in the SELECT list.
Going back to our piece of paper, the paper only stores one piece of data: Title. If we’re looking at our piece of paper, and we w3ant the Author of a book, we’re out of luck. The Author isn’t there!! What are we going to do?!
Well, we will need to perform something called a “lookup” to get the other information we need.
The lookup process basically uses the pointer, and goes to the record in the clustered index and grabs the other information the query asks for (which is, of course, the Author in my example).
The lookup process can be slow, especially if we need to look up many columns.Thankfully, there is a way to keep SQL from needing to do a lookup. That solution is to ‘INCLUDE‘ the other column data in your nonclustered index. I have a full discussion about how to INCLUDE columns, and how it can help your query performance here:
What is an INCLUDED column in an index?
Tip # 3: SQL Server might abandon the use of the nonclustered index if it will need to do many lookups
If a nonclustered index exists for a table, but SQL determines it will need to do several lookups for a query, it might just abandon the use of the nonclustered index altogether and use the clustered index instead. You will likely see a clustered index scan operator in the execution plan.
Remember what I said earlier: The lookup process can be slow, especially if we need to look up many columns.
SQL might just choose to say “Screw this! Looking up all this data is taking too long!“, and just get everything it needs by scanning the clustered index where all the information it wants lives anyway.
Tip # 4: You can have more than one nonclustered index on a table
Remember, this is because nonclustered index data is stored in memory. I can easily grab another piece of paper and create another list, ordered by Author if I wanted to.
Tip # 5: You can specify more than one column as your nonclustered index key
For example, you could create a nonclustered index on the Author column. But what if you own more than one book by the same Author? You could choose to create a nonclustered index that orders entries by Author, then by Title:
CREATE INDEX idx_Author_Title ON Books(Author, Title)
Links
There is an awesome book out there called Pro SQL Server Internals that discusses everything you need to know about indexes. The book helped me out tremendously when I was trying to understand clustered and nonclustered indexes. It also discusses several other topics that are great to know about SQL Server. You won’t regret owning this book, trust me. Get it today!

Next Steps:
Leave a comment if you found this tutorial helpful!
Also, make sure you download your FREE Ebook:
FREE Ebook on Sql Server Indexes!
This FREE Ebook contains absolutely everything you need to know about indexes in Microsoft SQL Server, including:
- Clustered Indexes
- Nonclustered Indexes
- Unique Indexes
- Understanding the B-tree
Everything discussed in this tutorial can be found in the Ebook. This Ebook will definitely be a great resource for you to keep and reference throughout your career as a data professional. Get it today!
As touched on, a big part of nonclustered index performance is to sometimes INCLUDE other column data. I have a full discussion about how to INCLUDE columns into a nonclustered index and how it can improve your query performance:
What is an INCLUDED column in an index?
You should also check out my full tutorial on the B-Tree. The B-Tree is a data structure that makes clustered and nonclustered indexes possible. Definitely check it out:
The B-Tree: How it works, and why you need to know
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, leave a comment or even better, send me an email!


