

There are several ways we can guarantee unique values in our primary key columns in our SQL Server tables. One data type we can use to store unique values is the UNIQUEIDENTIFER.
In this very brief tutorial, we’ll talk about what the SQL Server UNIQUEIDENTIFIER data type is and how it can help us guarantee uniqueness among the rows in our tables.
We’ll discuss these topics:
- What is the UNIQUEIDENTIFIER data type?
- How to populate a UNIQUEIDENTIFIER column
- Examples of a UNIQUEIDENTIFIER column
- The downside of the UNIQUEIDENTIFIER data type
- Tips, tricks, and links
This data type is listed in the following FREE guide:
FREE guide on the Top 10 data types you need to know!
This guide discusses the most common data types you will encounter during your career as a database professional, including the UNIQUEIDENTIFIER data type. This guide will be an excellent resource for you to reference throughout your career. Download it today!
Let’s get into it.
1) What is the UNIQUEIDENTIFIER data type?
The UNIQUEIDENTIFIER data type is meant to store unique values that are truly unique across space and time.
Columns with the UNIQUEIDENTIFIER data type are meant to store Globally Unique Identifiers (GUID’s). In other words, no two UNIQUEIDENTIFIER values will be the same in any database within your entire SQL Server environment.
Sometimes we need to maintain data across two or more databases, and we need to make sure the primary keys in those databases are all unique. The UNIQUEIDENTIFIER data type is the best tool we have to accomplish that.
You could set up the UNIQUEIDENTIFIER data type on a non-primary key column, but that would be weird. The whole reason you would use the UNIQUEIDENTIFIER data type is because you want your values to be unique, and the best way to enforce uniqueness is through a primary key constraint.
2) How to populate a UNIQUEIDENTIFIER column
There are two ways we can populate a UNIQUEIDENTIFIER column with values. We can use either the NEWID() system function or the NEWSEQUENTIALID() system function.
The NEWID() system function:
Here’s a very simple example of calling the NEWID() system function to generate a GUID value:
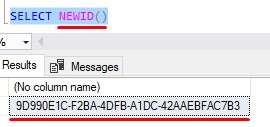
That’s quite the value. SQL Server guarantees uniqueness simply because there is a nearly unlimited combination of alpha-numeric characters that can be used for the GUID.
If we want to insert a new GUID into a UNIQUEIDENTIFIER column, we can simply call NEWID() from within an INSERT statement:
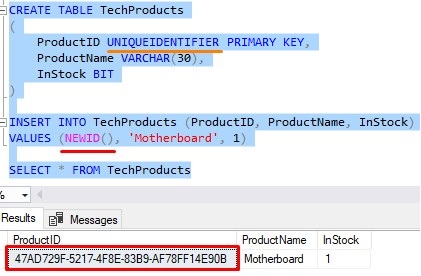
Very simple.
Our TechProducts table uses the UNIQUEIDENTIFIER data type on the ProductID column. This column is also identified as the primary key of the table. If we remember from our clustered index tutorial, a clustered index is automatically created on columns you identify as being the primary key column. Here’s the clustered index created for our TechProducts table, seen in the Object Explorer:
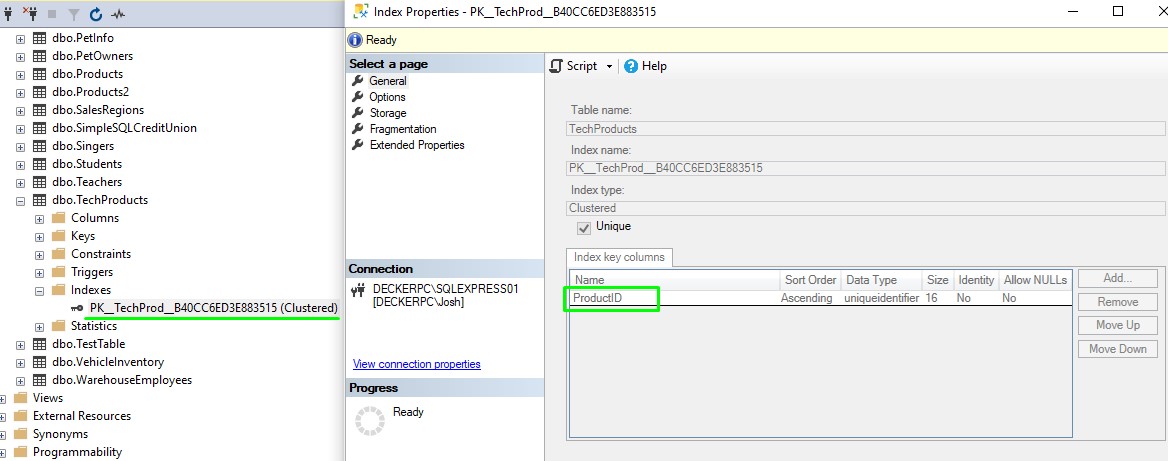
The NEWSEQUENTIALID() system function:
The NEWSEQUENTIALID() function is similar, but has it’s own set of rules. The GUID’s generated by this function will be created sequentially, meaning the GUID’s are generated in some kind of logical order. This usually means the next GUID will be slightly greater than the last GUID.
This method of generating a GUID is preferred because sequential ID’s are excellent for the clustered index data structure, which is usually placed on a primary key column. The best clustered index key is a column with ever-increasing values simply because new rows can be tacked onto the end of the clustered index data structure (instead of somewhere in the middle).
Take a look at my full beginner-friendly tutorials on clustered indexes and the B-tree (which is the data structure used for the clustered index):
SQL Server Clustered Index: The Ultimate Guide for the Complete Beginner
The B-Tree: How it works, and why you need to know
Unlike the NEWID() function, one does not simply call this function. If you try, you get an error message:
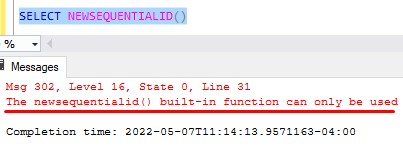
Here’s that entire error message:
The newsequentialid() built-in function can only be used in a DEFAULT expression for a column of type ‘uniqueidentifier’ in a CREATE TABLE or ALTER TABLE statement. It cannot be combined with other operators to form a complex scalar expression.
We get the same error message if we try to use NEWSEQUENTIALID() in an INSERT statement. As the error message implies, you can only use the NEWSEQUENTILID() function in a default constraint on a column. We’ll walk through how to set that up in the next section.
3) Examples of a UNIQUEIDENTIFIER column
We already briefly looked at one example of setting up a UNIQUEIDENTIFER column in a TechProducts table. We saw how we can call the NEWID() function to generate a new GUID on inserts.
Let’s see how you would set up a default constraint on the ProductID column of our table:
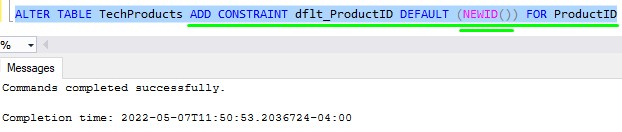
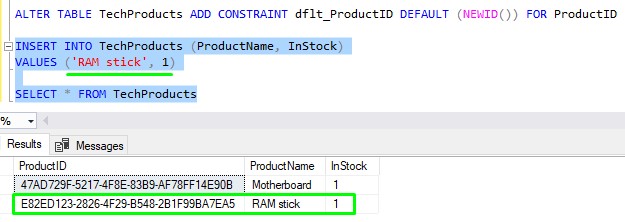
Now when a new row is inserted into the TechProducts table, we don’t need to specify a value for the ProductID column. The NEWID() function will get called automatically and use the resulting GUID as the ProductID value for the row:
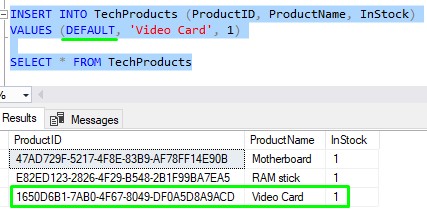
If we wanted to be explicit, we could use the ‘DEFAULT‘ keyword in our column values list:
Let’s drop the constraint and re-create it using the NEWSEQUENTIALID() function as the default value instead:
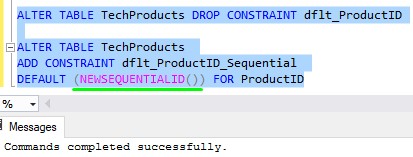
Now we’ll insert three new rows into the table:
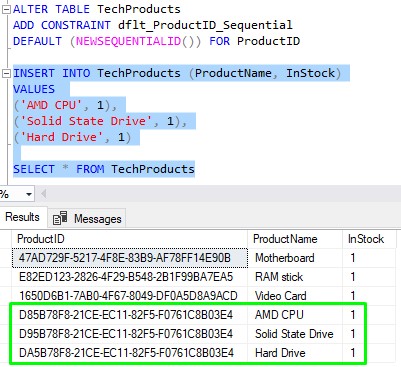
Notice the GUIDs for these three rows are nearly identical (of course, “nearly” being the operative word). These GUIDs are growing sequentially, meaning the GUIDs follow some kind of logical order. This is preferred for the clustered index data structure.
4) The downside of the UNIQUEIDENTIFIER data type
Folks, like all things in SQL Server, there’s a downside to using UNIQUEIDENTIFER. It requires a huge amount of space to store a single GUID value. Each GUID uses 16 bytes of storage.
Compare that to regular ol’ INT that uses 4 bytes to store a value.
As discussed in the primary key tutorial, one reason a clustered index key of the INT data type is preferred is because of how little space is required to store each value. We always need to be aware of how much space we’re using to store values.
But of course, integers aren’t guaranteed to be unique across space and time, which is the benefit of UNIQUEIDENTIFIER.
5) Tips, trick, and links
Here are some helpful tips you should know about the UNIQUEIDENTIFIER data type:
Tip # 1: UNIQUEIDENTIFIER is just a data type. It does not enforce uniqueness
The UNIQUEIDENTIFIER data type and the primary key constraint go hand and glove. It would be strange to create a column using the UNIQUEIDENTIFIER data type and not make that column the primary key.
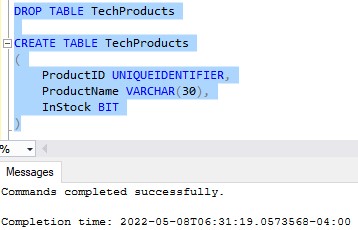
To show you what I mean, let’s drop the TechProducts table and re-create it without specifying a primary key constraint:
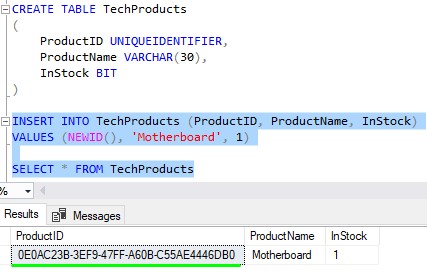
Then we’ll add a row to our table:
Understand there is nothing stopping me from inserting another row with the same ProductID value:
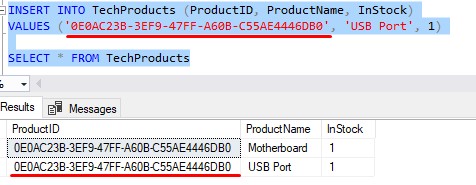
So again folks, the UNIQUEIDENTIFIER data type on it’s own does not enforce uniqueness. Uniqueness is enforced by the primary key constraint that you usually place on the UNIQUEIDENTIFER column.
Tip # 2: Remember, the only way you can use NEWSEQUENTIALID() is through a default constraint
We cannot call NEWSEQENTIALID() on the fly. The only way it can be used is within a default constraint on a column.
Check out the full beginner-friendly tutorial on default constraints to learn more:
SQL Server Default Constraint: A Guide for Beginners
Links:
There is a great book called Pro SQL Server Internals by Dmitri Korotkevitch that you should get your hands on. It goes over everything you need to know about the UNIQUEIDENTIFIER data type. It also goes into excellent detail about clustered indexes and the B-tree. If you understand these topics, you’ll basically understand the root of query performance. You won’t regret owning this book, trust me. I reference it all the time. Get it today!

Next Steps:
Leave a comment if you found this tutorial helpful!
Do you know these 6 rules about the primary key constraint? Check out the tutorial to find out!
We also talked about clustered indexes and the B-tree quite a bit in this tutorial. Understanding these topics is essential for understanding how to write efficient queries in Microsoft SQL Server. Check out the full tutorials to learn how they work:
SQL Server Clustered Index: The Ultimate Guide for the Complete Beginner
The B-Tree: How it works, and why you need to know
Finally, make sure you download your FREE guide:
FREE guide on the Top 10 data types you need to know!
This guide discusses the most common data types you will encounter during your career as a database professional, including the UNIQUEIDENTIFIER data type. This guide will be an excellent resource for you to reference throughout your career. Download it today!
Thank you very much for reading!
Make sure you subscribe to my newsletter to receive special offers and notifications anytime a new tutorial is released!
If you have any questions, please leave a comment. Or better yet, send me an email!


